Pure Storage vs NetApp vs Dell PowerStore: Comparing Storage Solutions for the AI Era (2026)
Pure Storage vs NetApp vs Dell PowerStore compared on controller architecture, flash media, scaling, cyber resilience, and the enterprise AI data path. A 2026 technical guide for IT leaders choosing a primary all-flash array.
.png)
A GPU cluster runs at the speed of the data path feeding it. That single constraint reframes how I evaluate Pure Storage FlashArray, NetApp AFF, and Dell PowerStore in 2026, because the primary all-flash array you pick for databases and virtual machines is a separate decision from the platform that keeps thousands of GPUs saturated during training.
Both decisions sit inside the same vendor relationship, and getting the split right is where AI is forcing a rethink of storage and data fabrics.
This guide works through controller architecture, flash media, scaling behavior, the AI data path, and the data services that decide an estate. The goal is to give you arguments you can act on, grounded in current platform specifications.
One naming note before the technical work. Pure Storage now operates as Everpure after a February 2026 corporate rename, and the FlashArray and FlashBlade product names continue. I use Pure throughout for recognition.
Controller architecture and failure behavior
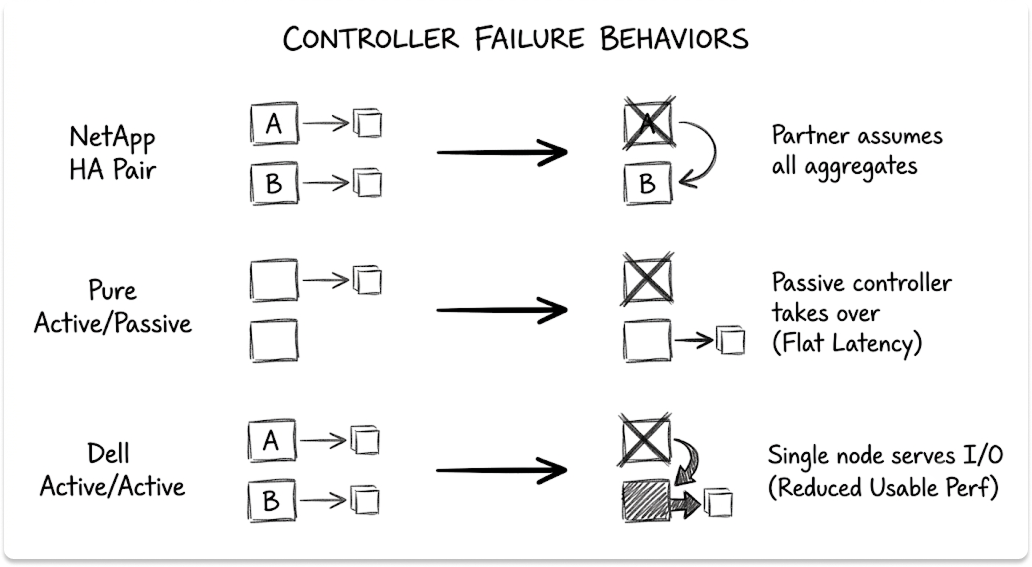
The controller design governs how an array serves I/O and how it behaves the moment hardware fails.
Pure FlashArray runs a dual-controller design. Independent analysis describes the pair as effectively active/passive to the media, where both controllers keep host ports live but one processes I/O to flash at a time.
Pure sizes each controller to carry 100 percent of rated performance at roughly half load during normal operation, so a controller loss leaves performance flat. That choice favors predictable latency through a failure over peak aggregate throughput.
PowerStore runs both nodes in an appliance as active/active, serving I/O to the same volumes at once. You get more usable performance from the pair, and you size with the understanding that a node loss removes real capacity until it returns.
NetApp AFF uses high-availability pairs where each node owns a set of aggregates and serves its own workloads, with the partner assuming ownership during a failure. Across a cluster you add pairs and distribute volumes, which is why ONTAP reaches higher node counts than the other two.
The data-protection scheme follows the same split. Pure uses RAID-3D with N+2 protection and no dedicated hot spares, rebuilding into free space with background processes. PowerStore uses its Dynamic Resiliency Engine for distributed parity. NetApp uses RAID-DP and RAID-TEC.
Flash media and rack density
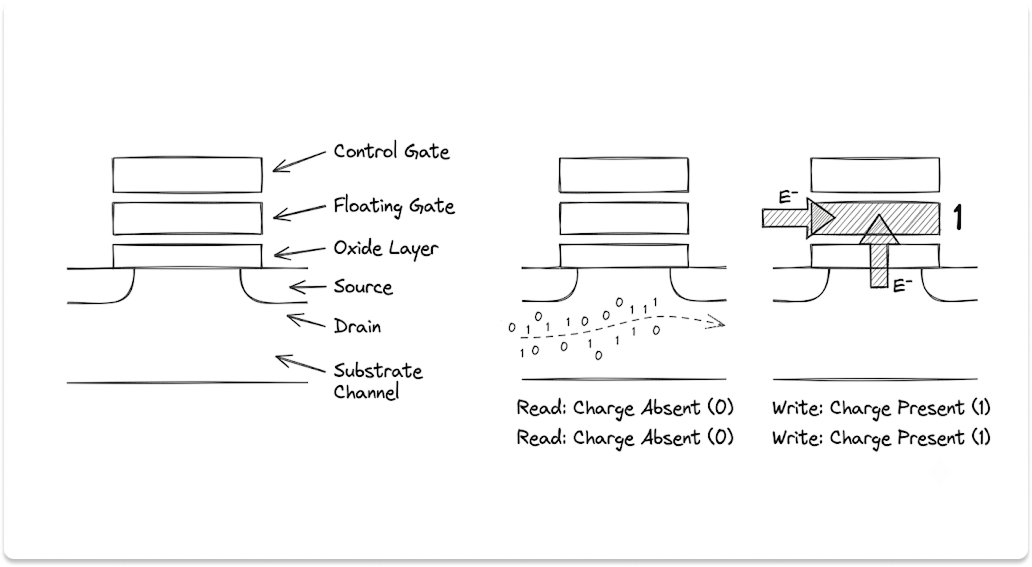
The flash itself is a real architectural fork that shows up in density, endurance, and tail latency.
Pure designs its own flash. A DirectFlash Module presents raw NAND to Purity with no flash translation layer and no on-drive garbage collection, so the software manages wear leveling and block reclamation globally with line of sight to every die.
Pure ships 75TB QLC and 36TB TLC modules reaching about 1.5PB in 3RU. The payoff is longer flash life and deterministic I/O, since the software never waits on a drive that decided to clean itself mid-request.
Dell and NetApp ride the commodity NVMe SSD supply chain, which speeds adoption of each NAND generation and lowers media cost. The PowerStore Gen 3 platform moved to E3.S drives at 40 bays in a 3U chassis, roughly 13.3 drives per rack unit, and runs TLC or QLC media in the same model with no performance penalty for QLC. NetApp scales drive count through NS224 NVMe shelves and added nodes.
Density and power feed directly into the CIO power and capacity math for AI build-outs, where rack space and watts per usable terabyte set the ceiling on how much GPU you can stand up in a given facility.
Scaling models and performance ceilings
Vendor performance figures come from controlled labs, so read each as a ceiling. The shape still tells you how the platform grows.
NetApp publishes the highest aggregate ceiling because it scales out furthest, reaching up to 40 million IOPS and around 1TBps across a cluster on the A-Series, with up to 185PB effective on the higher models. That headroom appears when a workload spreads across many nodes.
Pure pushes single-system latency. The FlashArray//ST targets 10 million IOPS, and FlashArray//XL R5 advertises sub-150-microsecond latency. The family scales up, so you reach higher tiers by moving to a larger model.
PowerStore clusters multiple appliances and grows capacity within an appliance. The Gen 3 reset, announced in May 2026 and shipping in July, moved the inter-node fabric to 200GbE RDMA on the larger 5500 and 9500 models and added mixed-generation clustering so a Gen 3 appliance joins an existing Gen 2 cluster.
The AI data path: GPUDirect Storage and where the block array fits
The mechanism that matters for AI is the path between storage and GPU memory. NVIDIA Magnum IO GPUDirect Storage lets a GPU pull data directly from storage over RDMA, bypassing the CPU and system memory, which removes a copy and cuts latency. Around it sit NFS over RDMA, pNFS, and RoCE on the network side.
A primary all-flash block and unified array serves the parts of an AI estate that look like classic enterprise workloads. That includes the transactional databases behind feature stores, the virtual machines running inference services, and the structured data feeding pipelines. For where that structured layer lives, the data platform decision between Snowflake, Databricks, and BigQuery often sits alongside the storage choice.
Large-scale training, checkpointing, and retrieval at scale run on scale-out file, object, and parallel platforms that present a single namespace and stream at extreme throughput over GPUDirect Storage.
This is the split each vendor handles with a different architecture, and it is the most decision-relevant technical point in the comparison. Fragmented data across these tiers is what stalls projects, which is why turning fragmented information into real AI value is as much a storage architecture question as a data science one.
Gartner projects that inadequate AI-ready data will cause 60 percent of AI initiatives to be abandoned by 2026, and the storage layer carries much of that risk.
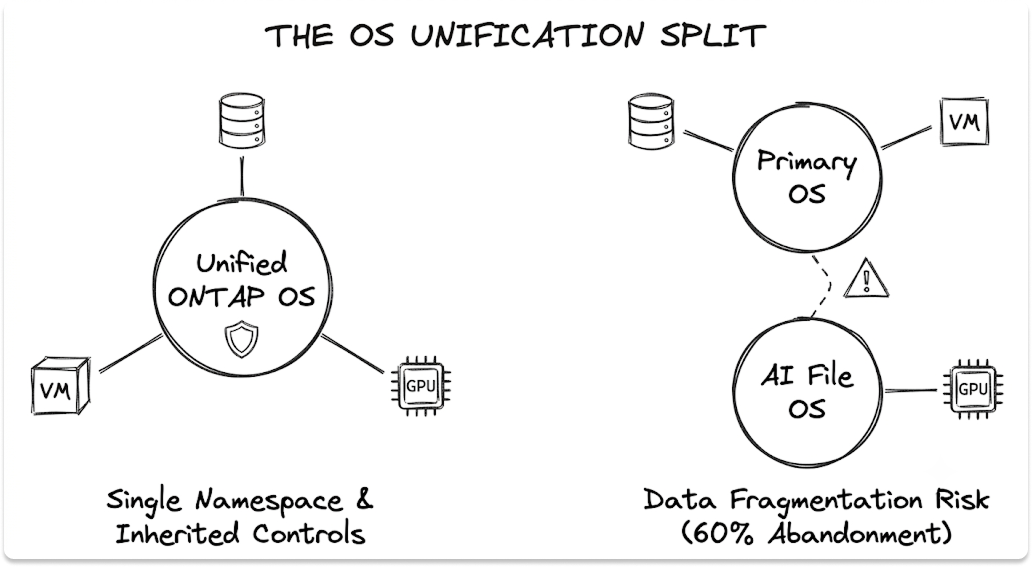
NetApp: one operating system from primary to AI
NetApp runs ONTAP across the primary AFF arrays and the AI-scale tier, which keeps one data-services model and one namespace across both.
The AFF A90 is validated for NVIDIA DGX SuperPOD and certified as NVIDIA-Certified Storage, so the same array running production NAS extends into GPU work. For AI at scale, the NetApp AFX system runs a disaggregated build of ONTAP that decouples performance from capacity and is certified for DGX SuperPOD with DGX GB300 systems.
The performance work is concrete. NetApp recorded 457 GiB/s of sustained throughput across eight AFX nodes under GPUDirect Storage, a 33 percent gain over the prior year achieved with one-eighth of the capacity, building on 171 GiB/s on an AFF A800 cluster in 2023 and 351 GiB/s on AFF A90 in 2024. AFX scales linearly toward 128 nodes, and optional DX50 nodes run a global metadata engine for real-time cataloging.
On top sits the AI Data Engine, an ONTAP-integrated service that handles in-place vectorization, semantic search, change detection, and policy guardrails for retrieval-augmented generation and inference, aligned to the NVIDIA AI Data Platform reference design with NIM microservices.
The practical effect for an existing NetApp shop: the AI tier inherits SnapMirror replication, snapshots, and ransomware controls already in production.
Pure Storage: FlashArray for primary, FlashBlade for AI scale
Pure pairs FlashArray for block and unified workloads with FlashBlade for the scale-out file and object work that GPU clusters need, and both run Purity on DirectFlash.
FlashBlade//S is a certified storage solution for NVIDIA DGX SuperPOD with GPUDirect Storage support, using a distributed transactional database for parallelism and reaching 1.4TB of effective capacity per watt.
FlashBlade//S R2 is certified for DGX SuperPOD with DGX GB200 and GB300 systems, connecting via 16 ports of 400GbE over RoCE per system.
For the largest training and HPC environments, FlashBlade//EXA splits into a metadata core and data nodes that scale independently, reaching exabyte scale with write throughput up to half of read performance in a single namespace.
Pure also integrated the NVIDIA AI Data Platform reference design into FlashBlade and offers turnkey GenAI Pods that deploy NeMo, NIM microservices, and the Milvus vector database through Portworx Data Services.
The design language carries across both platforms through Purity and DirectFlash, while the platforms themselves are distinct, so an estate sizing for both block primary and AI scale plans for two systems.
Dell PowerStore: primary unified array, with PowerScale and Lightning for AI
PowerStore covers block and file in one appliance and, with Gen 3, added container workload support and tighter cyber telemetry through PowerStoreOS 5.0. Dell positions its AI-scale storage on separate platforms built for unstructured throughput.
PowerScale is the scale-out NAS for AI, running OneFS to 252 nodes and 186PB in a single namespace with GPUDirect Storage and NFS over RDMA. The F710 became the first Ethernet-based storage certified for NVIDIA DGX SuperPOD and carries a 2:1 data reduction guarantee.
For inference, using PowerScale as a KV-cache offload layer has shown up to a 19x boost in time-to-first-token in Dell-tested configurations.
At the top of the range, Dell introduced Lightning File System, a parallel file system delivering up to 6TB/s per rack for environments running tens of thousands of GPUs, and Exascale Storage that runs PowerScale, ObjectScale, and Lightning as personalities on shared PowerEdge hardware.
Dell also reported pNFS in OneFS delivering up to 6x faster large-file performance than NFSv3 with 800GbE connectivity on Exascale. PowerStore's role in this estate is the block and unified tier feeding databases and virtual services around the GPU cluster.
The decision-relevant pattern in that table: NetApp keeps primary and AI storage under one operating system, while Pure and Dell run a distinct AI-scale platform alongside the primary array.
Data services and cyber resilience for AI estates
The services layer carries weight once data moves through training, RAG, and inference, where a poisoned or unrecoverable dataset corrupts model output.
ONTAP serves NFS, SMB, S3, and the full block set from one operating system, with SnapMirror replication and FabricPool tiering to cloud object stores.
Its Autonomous Ransomware Protection with AI detects abnormal activity with a claimed 99 percent accuracy and takes a locked snapshot automatically, backed by SnapLock and tamperproof snapshots for immutability and multi-admin verification for deletion control.
Pure delivers immutability through SafeMode snapshots that resist deletion, modification, and encryption even with administrative credentials, with file services native in Purity and object on FlashBlade.
PowerStore provides secure immutable snapshots today, distributed data protection through DRE, and Dell Cyber Detect for PowerStore scheduled for Q3 2026 using PowerStoreOS 5.0 telemetry for inline detection.
These controls connect directly to recovery planning. The question of how you fight ransomware when there is nothing left to restore turns on immutable copies and tested restore paths, and sizing those copies against your service levels is where an enterprise backup comparison by RPO and RTO earns its place beside the array decision.
Data reduction guarantees and what they measure
The headline ratios are close to meaningless in isolation because each vendor measures a different thing. Pure guarantees 5:1 from deduplication and compression.
NetApp guarantees 4:1 for SAN and 1.5:1 for NAS. Dell raised PowerStore to a 6:1 guarantee on Gen 3 with PowerStoreOS 5.0, while PowerScale carries 2:1 for unstructured AI data.
A 6:1 figure and a 1.5:1 figure can describe the same physical efficiency on the same data, because one vendor counts thin provisioning, clones, and snapshots and another excludes them.
Compare the guarantee mechanism instead: each vendor ships extra capacity at no charge if your real ratio falls below the floor, so read which workloads qualify, what counts toward the ratio, and whether the guarantee survives a controller upgrade.
Use the Questionnaire below to see which storage solution suits you
How to decide
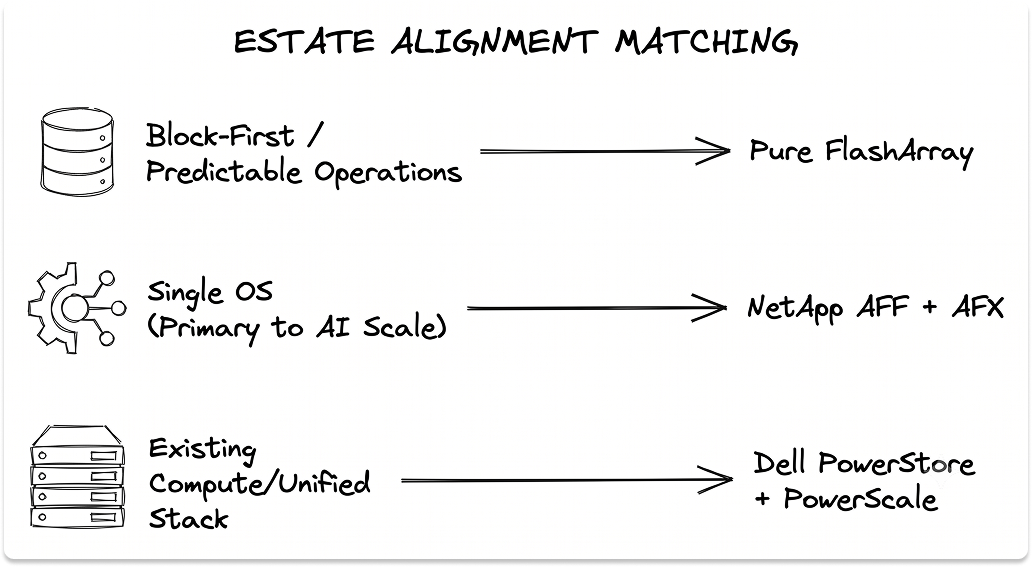
Map the architecture to the workload, and the choice gets decisive.
- Block-first primary storage with simple operations. Choose Pure FlashArray. The active/passive design holds latency flat through a controller loss, Purity runs cleanly with a small team, and DirectFlash gives deterministic I/O. Plan for FlashBlade as the separate file and object tier if AI scale enters the estate.
- Unified block and file in a Dell environment. Choose PowerStore, with one vendor across compute, storage, and support, true dual-active controllers, and container workload support on Gen 3. The AI-scale tier moves to PowerScale and, at the outer edge, Lightning File System.
- Multiprotocol consolidation and AI under one operating system. Choose NetApp AFF, extending into AFX for AI. ONTAP serves NFS, SMB, S3, and block with one data-services model, SnapMirror, and on-box ransomware detection, and the AFX tier inherits all of it.
- Large-scale GPU training as the driver. Match the AI platform to the estate you already run: FlashBlade//EXA for a Pure shop, AFX for a NetApp shop, PowerScale plus Lightning for a Dell shop. The shared-OS path keeps one namespace and one set of controls from primary to GPU tier.
Two estate factors override most spec-sheet preferences. A VMware-heavy environment in the post-Broadcom period changes the calculus across all three, and the virtualization platform decision between Hyper-V, VMware, and Nutanix often moves in lockstep with storage. An existing estate also carries gravity through SnapMirror, OneFS, or a Dell stack that raises the switching cost.
Whatever the shortlist, validate on your own data. Run a vendor proof of concept on two or three real applications, include a GPUDirect Storage throughput test if AI is in scope, and run your failure and recovery drills before signing. The platform that holds up under your I/O and your restore tests is the one that earns the deployment.
Choosing a Storage Solution is a 5-Year Decision
Pure, NetApp, and Dell are all strong, so the work is matching the architecture to your workloads and running a proof of concept on your own data. Compare pre-vetted storage, data, and AI infrastructure vendors on TechnologyMatch, filtered to your estate and constraints. You stay anonymous until you reach out, you pick who to talk to, and it is always free to buyers.
FAQ
What is the main difference between Pure Storage, NetApp, and Dell PowerStore?
Pure FlashArray is a block-first, scale-up array on custom DirectFlash media with active/passive controllers sized for flat latency. NetApp AFF runs ONTAP and scales out to 24 nodes with native NFS, SMB, S3, and block. Dell PowerStore is a dual-active, unified block and file appliance that clusters across appliances.
Which storage array is best for AI and GPU workloads?
The primary array serves the databases and VMs around the GPUs, while large training runs on scale-out platforms over GPUDirect Storage. NetApp uses AFX (disaggregated ONTAP to 128 nodes), Pure uses FlashBlade//S and //EXA, and Dell uses PowerScale and Lightning File System. NetApp uniquely keeps primary and AI storage on one operating system, ONTAP.
How do the data reduction guarantees compare?
Pure guarantees 5:1, NetApp guarantees 4:1 for SAN and 1.5:1 for NAS, and Dell PowerStore guarantees 6:1 on Gen 3. These numbers are not directly comparable because each vendor counts thin provisioning, clones, and snapshots differently, so compare the guarantee mechanism and validate the ratio on your own data.
Is Pure Storage controller architecture active-active or active-passive?
Within a single FlashArray, the dual controllers operate active/passive to the media, where both keep host ports live but one processes I/O to flash at a time. Each controller is sized to carry full rated performance, so a controller loss leaves latency flat. ActiveCluster is a separate metro stretch capability between two arrays.
Which platform is best for ransomware protection and cyber resilience?
NetApp ONTAP has on-box Autonomous Ransomware Protection that detects attacks and takes a locked snapshot automatically, with SnapLock and multi-admin verification. Pure offers SafeMode immutable snapshots that resist deletion even with admin credentials. Dell PowerStore provides secure immutable snapshots today, with on-box Cyber Detect arriving in Q3 2026.