How to Audit Your Endpoint Security Stack Before Deploying AI Agents
Most endpoint security stacks have zero visibility into what AI agents are actually doing. This guide covers the 5 audit checks every IT leader must run before deploying AI agents — from MCP server vulnerabilities to process tree lineage, agent identity scoping, and runtime guardrails.
In December 2025, security researchers published 24 CVEs across GitHub Copilot, Cursor, and Claude Code. These weren't server-side bugs or cloud misconfigurations. They lived on developer endpoints.
The underlying flaw in most of them was identical: an AI agent operating as a high-privilege deputy for its user, manipulated into weaponizing its own legitimate access against the organization.
This is the Confused Deputy Problem. AI agents don't need to be exploited the way malware exploits a vulnerability. They need to be manipulated. And manipulation doesn't look like a threat to your current stack.
Your EDR was built to catch malware arriving from outside. It was not built to watch a trusted, locally-running agent read a confidential file, pass its contents to an API, format the output, and transmit it to an external destination across four separate steps, none of which trigger an alert in isolation. That is a structural gap in your coverage.
Before any AI agent touches a production environment, these five checks must run.
Why Traditional Endpoint Security Has a Structural Blind Spot for AI Agents
The Confused Deputy Problem
AI agents inherit the full session privileges of their user, but they make runtime decisions that were never explicitly programmed. An attacker doesn't need a zero-day. They need to manipulate the agent into using access it legitimately holds.
CVE-2025-59536 is a precise example. A malicious commit to a shared repository hijacked the execution context of every developer who cloned the project. The attacker used a manipulated deputy with write access to the filesystem and an active shell. Your current threat detection model was not designed to catch that pattern.
The Four Event Types Your EDR Is Not Watching
Traditional EDR monitors network traffic and known malicious process signatures. Endpoint AI agents generate a different telemetry signature entirely. The four event types your stack is currently missing:
- Process spawning triggered by agent tool calls
- Clipboard reads accessed by agents pulling context from user sessions
- Local file access through OS-level accessibility APIs that bypass network controls entirely
- API calls to developer-controlled infrastructure that never cross a network boundary a proxy can see
Legacy DLP rules aren't written for these event types. Standard SIEM queries don't look for them. The detection gap is structural, and you can't patch your way out of it.
The risk emerges across sequences of actions, not individual events. An agent reads a confidential file, passes its contents to an API, formats the output, transmits it to an external destination: four steps, zero alerts in isolation.
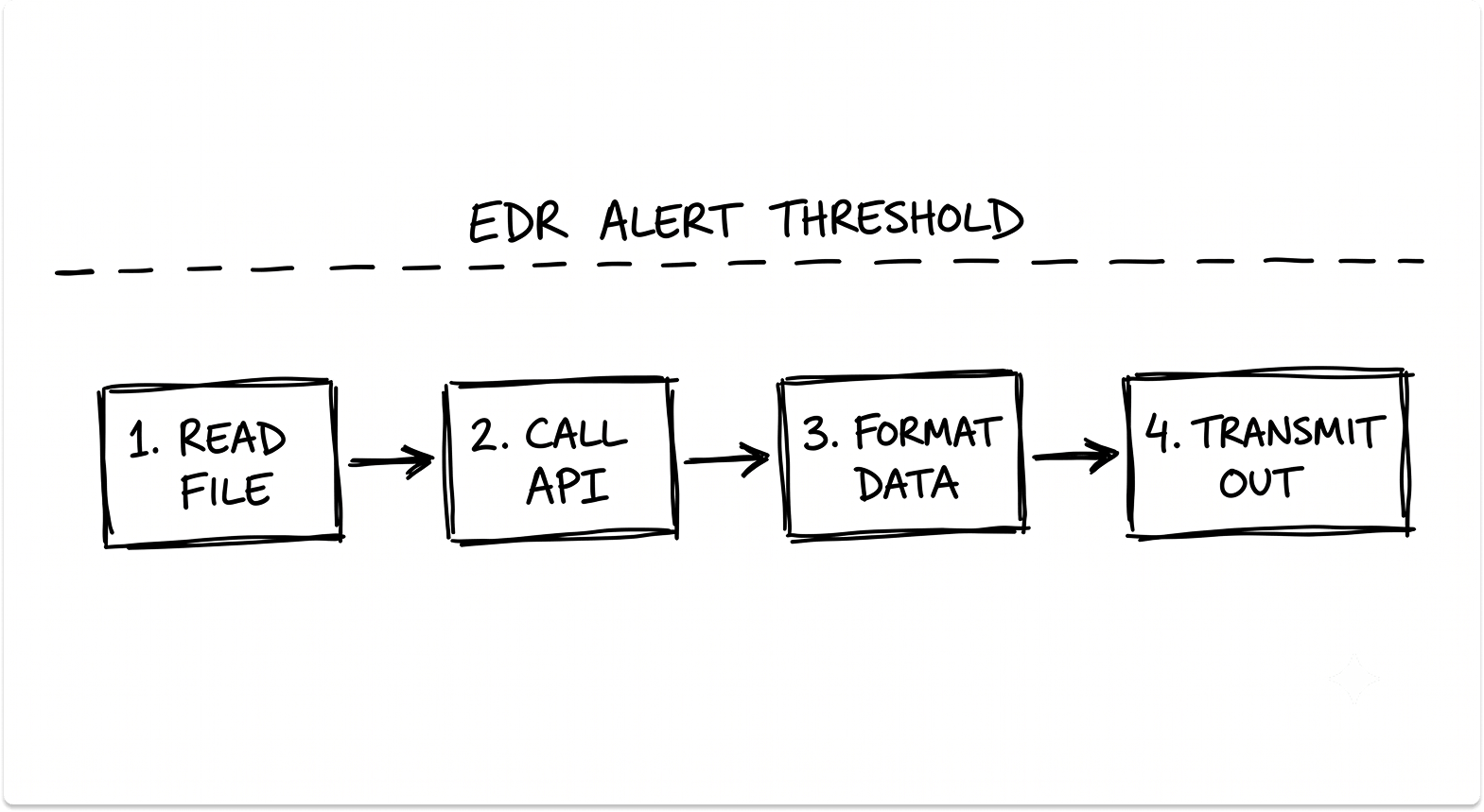
The Three Agent Deployment Patterns EDR Misses Entirely
Your EDR covers one of three deployment patterns, and only partially.
EDR vendors can see endpoint agents but are blind to SaaS and embedded agents running in third-party platforms. Point solutions that focus exclusively on endpoint coding agents are addressing one-third of the problem at best.
The 5 Audit Checks You Must Run Before Deploying AI Agents
Audit Check 1: Build a Live Agent Inventory With Blast Radius Scoring
Before you assess controls, you need to know what's running.
80.9% of technical teams have moved past the planning phase into active testing or full deployment. The average organization now manages 37 deployed agents. More than half run with no security oversight or logging.
Shadow AI makes this harder. A shadow agent maintains persistent state, remembers prior interactions, and applies that context to future decisions. Its blast radius covers systems, users, and time, and it doesn't reset between sessions.
An agent may have already accessed CRM data, read source code repositories, and sent outputs to developer-controlled infrastructure your security team doesn't govern.
For each agent, your inventory must capture:
- Who authorized it and when
- What credentials it holds, and whether they are shared API keys or scoped identities
- What tools it can call and with what parameter scope
- Whether it can spawn sub-agents (25.5% of deployed agents currently can)
- Whether it runs persistent sessions that survive user logout
That last field matters more than most checklists account for. CrowdStrike's white paper on securing AI at the endpoint documents agents like Claude Cowork that run in the background on a desktop and can be steered remotely from a mobile device.
A persistent, background AI agent with filesystem access is a new endpoint risk class, and most agent inventories don't have a field for it.
Tooling: CrowdStrike's Shadow AI Discovery Service (Spring 2026) identifies AI apps, agents, LLM runtimes, and MCP servers across endpoint and SaaS surfaces, including agents like OpenClaw via distinctive process signatures and default port 18789.
Audit Check 2: Test Process Tree Lineage, Not Just Process Execution
Most teams confirm that their EDR logs agent process starts. That's insufficient.
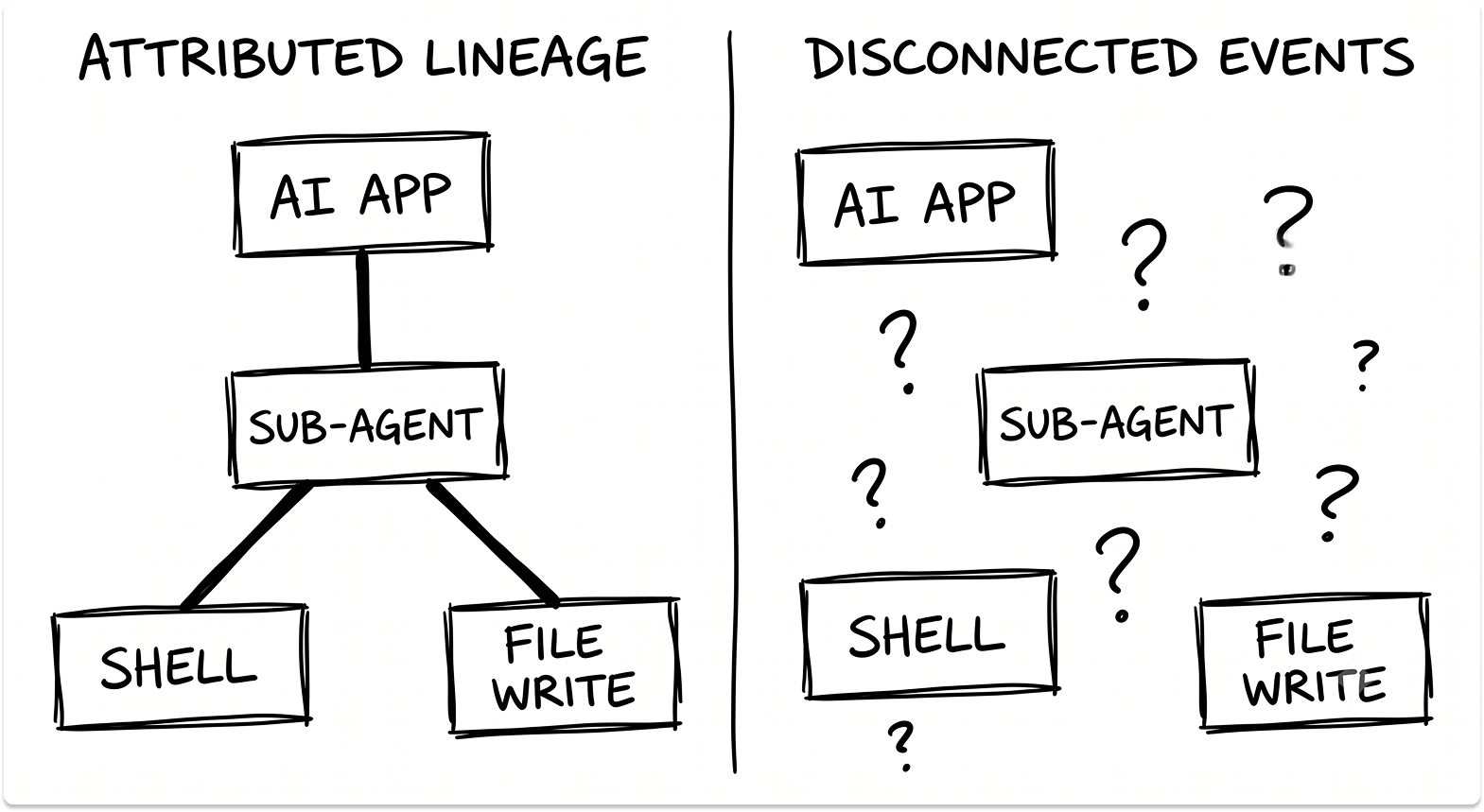
The question is more specific: can your EDR trace the full process tree from the parent AI application, through every sub-agent, shell command, and downstream system call, to the terminal execution point?
Without that lineage, you have event data but no attribution. When an incident happens, you won't know which agent caused it, what it was told to do, or what prompt triggered the action chain.
Run this controlled test before any production deployment:
- Deploy a sandboxed AI agent on an isolated endpoint
- Instruct it to execute a shell command, download a third-party package, call an external API, and write a file to the filesystem
- Pull the logs and check: are these actions recorded as a connected, agent-attributed lineage, or as disconnected process events attributed to a generic user session?
If you see disconnected events, you cannot do incident attribution. That is a hard blocker.
One important note on vendor limitations: SentinelOne Singularity offers solid runtime detection but has documented zero visibility into browser data leaks during agent sessions. Knowing your tool's specific blind spots matters as much as knowing what it covers. If your SOC can respond to alerts but can't reconstruct agent action chains, your incident response capability against this threat class is effectively zero.
Audit Check 3: Audit Agent Identity and Privilege Scope
The identity picture in most organizations is worse than confidence levels suggest.
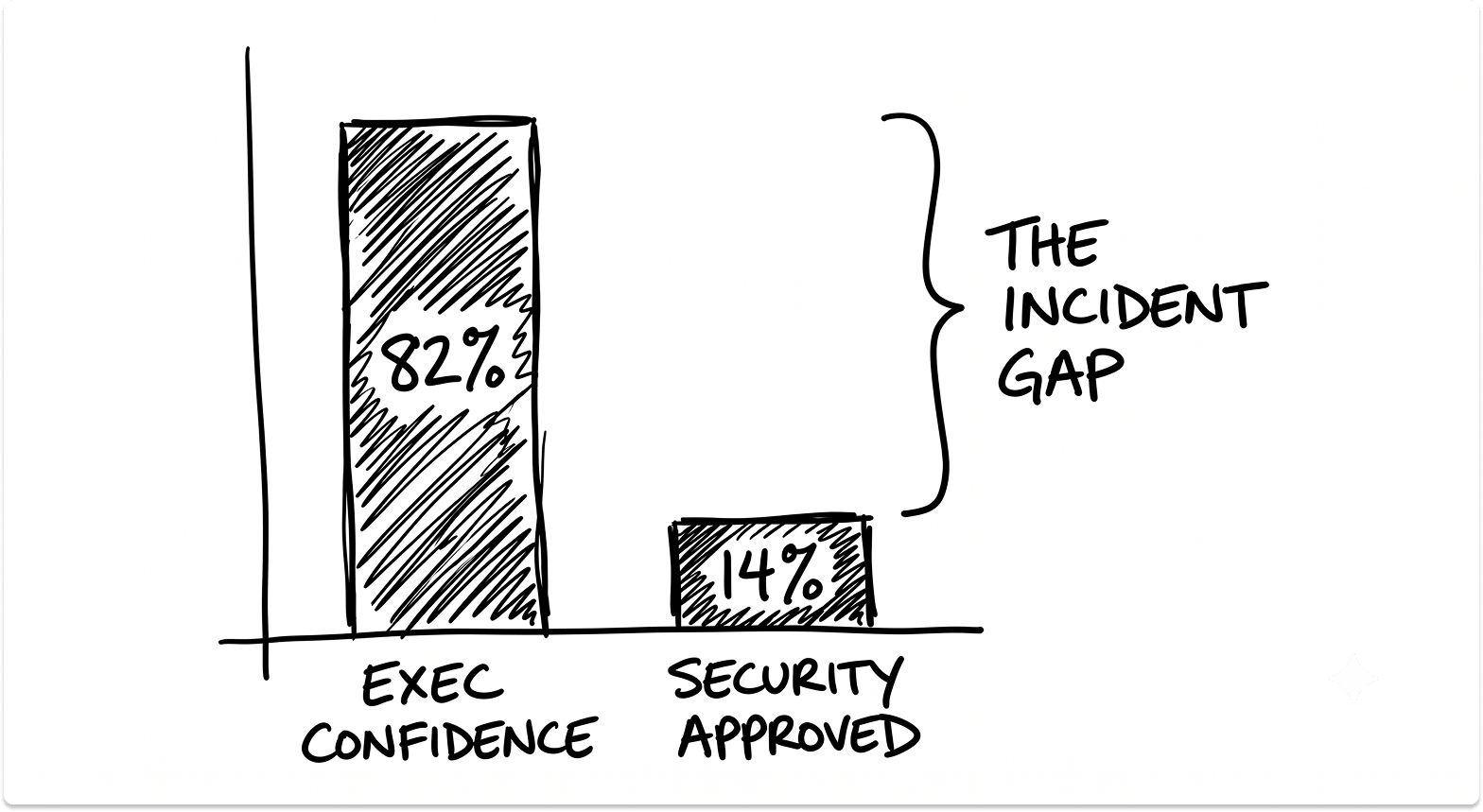
45.6% of technical teams rely on shared API keys for agent-to-agent authentication. Only 21.9% treat AI agents as independent, identity-bearing entities with their own access scopes.
Meanwhile, 82% of executives report confidence in their existing AI policies, yet only 14.4% of organizations send agents to production with full security or IT approval.
The confidence gap is where incidents start.
A practical test: ask what access you'd give a new contractor on day one. Your agent should have less than that, scoped specifically to the task it performs. Permissions must be scoped per tool, not per agent.
A single prompt injection into a broadly-scoped agent gives an attacker access to everything that agent can reach. CVE-2025-64755 demonstrated this precisely: a Claude Code privilege escalation flaw turned one under-scoped agent into a full escalation path.
Run a blast-radius assessment for every agent in your inventory. Map what an attacker can reach if that agent is compromised. Check OAuth token scopes and long-lived secrets.
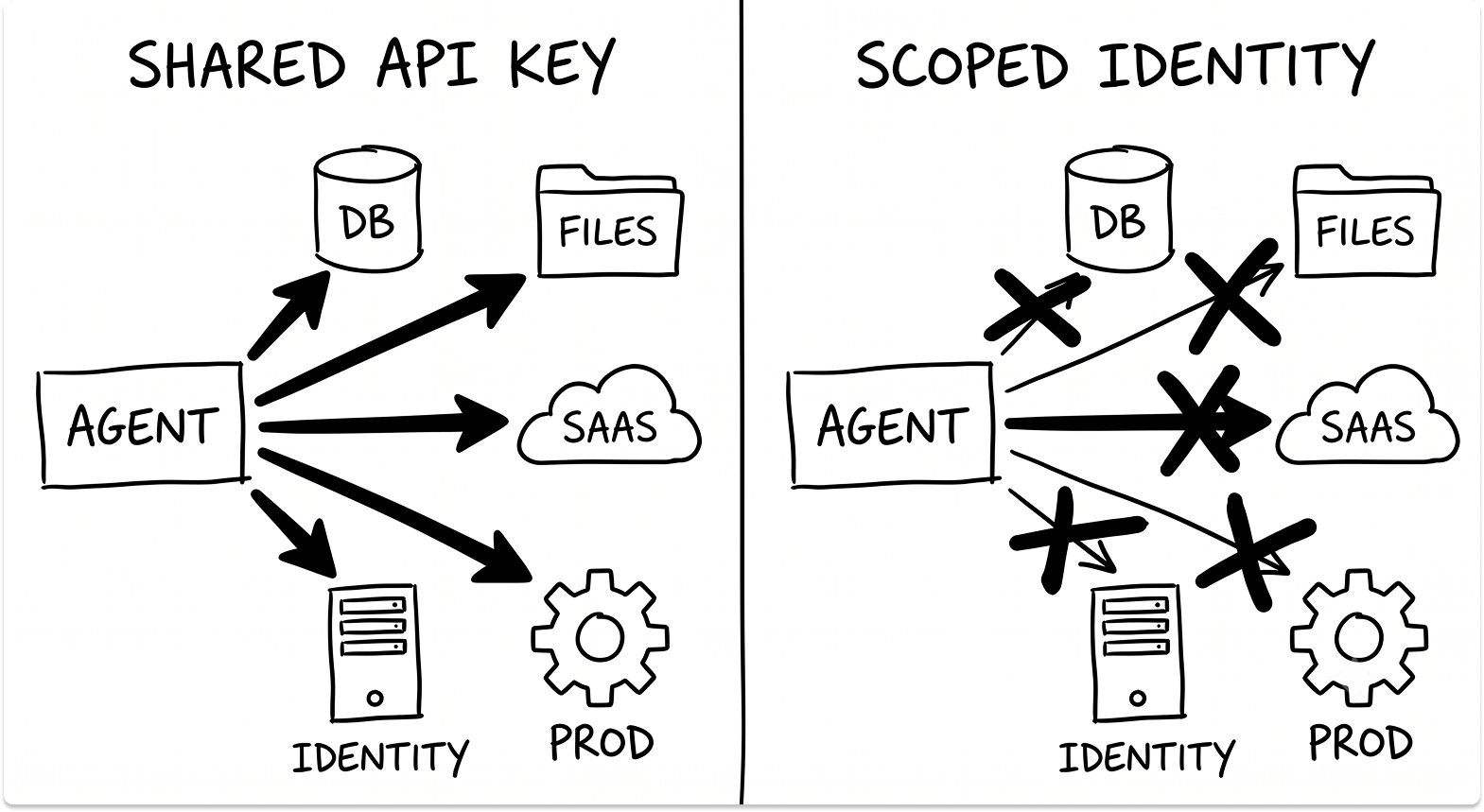
If a single agent compromise can reach production databases, customer data, or identity infrastructure, that agent is not ready for production. This connects directly to IAM governance failures that are already a documented failure pattern in hybrid environments. Agents amplify those problems — they don't resolve them.
Audit Check 4: Validate Your MCP Server Security Posture
MCP servers are the highest-value, least-scrutinized attack surface on developer endpoints right now. They run locally, frequently store credentials in plaintext, and operate with elevated permissions. Most security teams have no monitoring coverage on them.
The breach timeline from the last 12 months shows what unmonitored MCP exposure looks like at scale:
The April 2026 STDIO flaw deserves specific attention because it is architectural. The standard input/output transport in MCP allows direct configuration-to-command execution without sufficient input sanitization. This is a design characteristic of the protocol, and a patch does not fully resolve it.
Run these checks against every MCP server in your environment:
Audit Check 5: Validate That Runtime Guardrails Are Deterministic
The most common mistake in enterprise AI deployments is treating model-level safety as execution-level safety. They are separate things.
Model-level guardrails were bypassed in 72% of test cases for Claude Haiku and 57% for GPT-4o. The model that generated the behavior is the same model evaluating whether that behavior was safe. That is a design flaw, and it means you cannot rely on it as a control.
Guardrails must be enforced outside the LLM's reasoning loop. Validation needs to be deterministic code. An agent must be blocked from deleting a production database regardless of what its model generates.
Two specific controls most teams are missing:
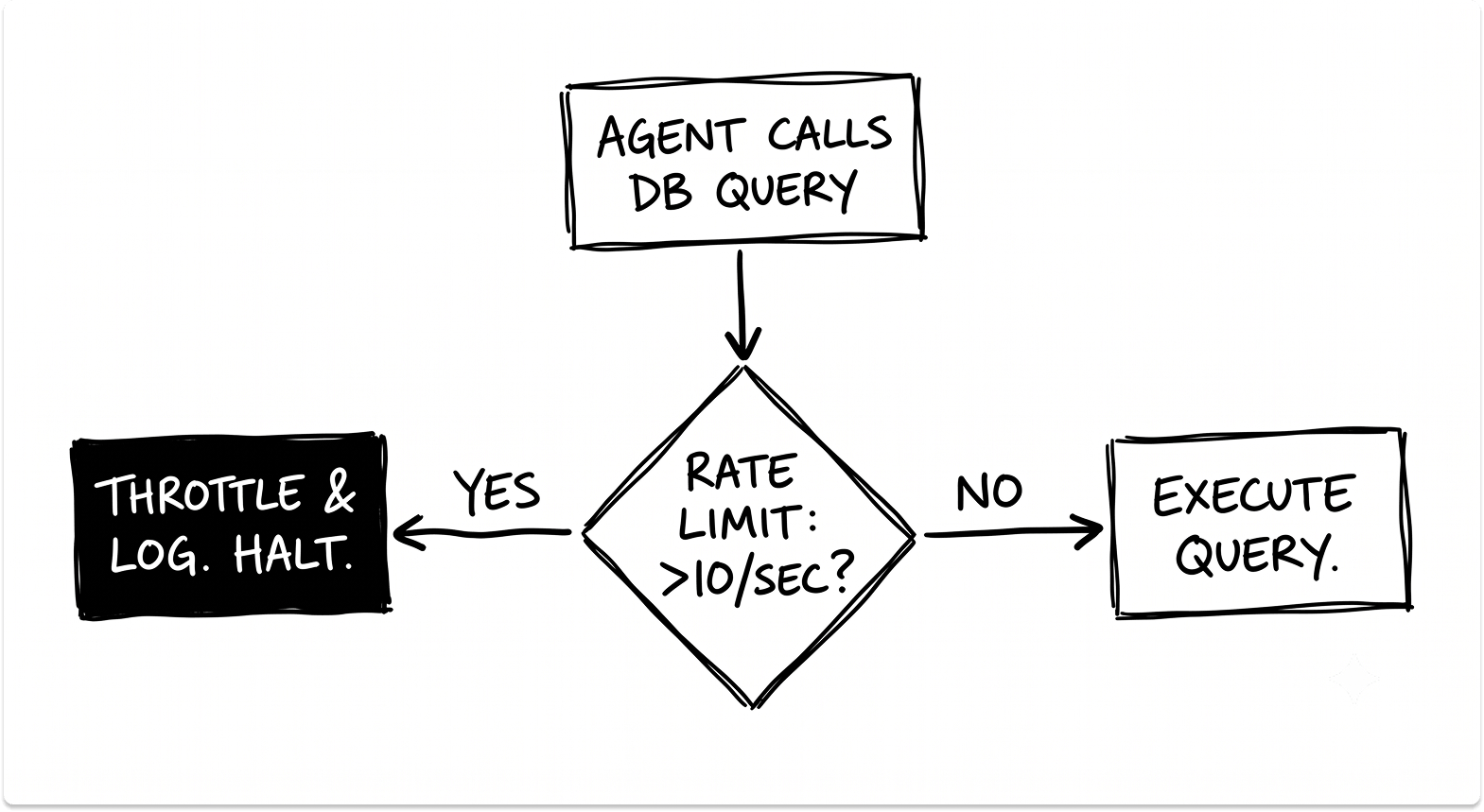
1. Circuit breakers at the tool level.
A system-wide kill switch is necessary, but it leaves a wide blast radius when it fires. Each tool should carry its own execution threshold. If a database query tool gets called 10 times in 10 seconds, it throttles automatically.
If a file-write tool gets triggered in a tight loop, it fails gracefully and logs the event. The goal is to isolate the failing component without taking down the entire workflow.
2. Input validation on every tool argument.
The LLM can generate malicious patterns without malicious intent: a bad SQL query, a path traversal string like ../../etc/passwd, an internal metadata service URL like 169.254.169.254.
These arrive as tool arguments. Sanitize them, validate them against an explicit schema, and reject anything outside the expected range before execution. This is standard defensive programming applied to a new input source.
Before you sign off on any agent deployment, answer these three questions:
- Can you log the full action chain — which tools were called, in what order, with what parameters, attributed to which specific agent?
- Can you detect behavioral drift — an agent executing actions that fall outside its intended task scope?
- Can you halt a specific agent action without shutting down the entire workflow?
If the answer to any of these is no, you have a control architecture problem.
The Compliance Blind Spot in Agent Monitoring
This doesn't appear in any current audit framework, and it should.
The monitoring infrastructure you build to protect against agent risk creates its own compliance exposure. Effective agent monitoring requires detailed behavioral telemetry: application usage, action sequences, geolocation, and user behavior patterns. Under GDPR and HIPAA, this data collection is regulated, and the monitoring asset you build is itself a regulated data asset.
Logging full agent conversation histories risks capturing PII, financial data, or health information. If that telemetry flows into your SIEM without a redaction pipeline, you have created a compliance liability in the process of closing a security gap.
Define data masking and redaction pipelines before logs are written to storage. Establish data retention policies for agent telemetry before you begin collecting it. The audit paradox applies here: your monitoring stack needs to be audited too.
This is especially relevant if you are operating in a regulated cloud environment where data residency requirements apply to logs and telemetry, not just primary data stores.
The Organizational Blind Spot No Tool Fixes
88% of organizations reported confirmed or suspected AI agent security incidents in the last year. Shadow AI incidents cost an average of $670,000 more than standard incidents.
Shadow AI is already running on your devices, deployed by individual teams without security review, connected to unmapped APIs and business systems your security team has never seen.
The gap is ownership, and most organizations haven't defined it.
When an AI agent causes an incident, who is accountable? The engineer who deployed it? The IT team that manages the endpoint? The InfoSec team that owns the EDR? In most organizations this question has no clear answer, which means it gets answered reactively, during an incident, under pressure.
Treat every AI agent as a production service. A production service has an owner, a defined purpose, documented permissions, and an audit trail. The same evaluation discipline you apply to external vendor tools should apply internally to agents your own teams build and ship. An agent that accesses customer data, runs shell commands, or calls external APIs is a production actor and should be governed as one.
Build a pre-deployment approval gate. Before any agent touches a production environment, require it to pass all five audit checks above and earn explicit security sign-off. Only 14.4% of organizations currently do this. That gap is where most incidents originate.
What a Passing Endpoint Audit Looks Like
These are outcome criteria. If your pre-deployment audit closes against all of them, your endpoint stack is ready for AI agents. If it doesn't, you know exactly where the gaps sit.
The endpoint audit is a continuous posture, not a one-time gate. Agent environments shift every time a new tool is connected, a permission is granted, or a package updates. Visibility, configuration hardening, and runtime protection need to run in parallel, on an ongoing basis.
The organizations that establish this now will know what their agents are doing, be able to attribute every action, and respond at machine speed. The ones that skip it are already running agents in production without that visibility. The breach timeline from the last 12 months shows exactly how that plays out.
Also read: How to use CHatGPT, Perplexity, Gemini, and Claude to build and IT vendor Shortlist
Find the vendors who close this gap
MCP security, agent visibility, runtime protection, identity scoping — browse pre-vetted vendors that fir your stack on TechnologyMatch. Anonymous until you engage first. Free and private.
FAQ
What is the Confused Deputy Problem in AI agent security?
The Confused Deputy Problem describes a scenario where an AI agent, acting as a high-privilege intermediary for a user, is manipulated into using its own legitimate access maliciously. An attacker doesn't need to exploit a vulnerability. They manipulate the agent's decision-making through crafted inputs — prompt injection, poisoned documents, or malicious tool descriptions — and the agent executes harmful actions using credentials and access it already legitimately holds.
Why doesn't my EDR catch AI agent threats?
EDR tools hook into system calls to detect malware signatures and anomalous process behavior. AI agents operating through MCP servers, IDE extensions, and API call chains generate a different telemetry signature: process spawning, clipboard reads, local file access, and API calls to developer-controlled infrastructure. Legacy DLP rules are not written for these event types, and the gap is architectural.
What is an MCP server and why is it a security risk?
MCP (Model Context Protocol) servers are local processes that connect AI agents to external tools, data sources, and APIs. They frequently store credentials in plaintext config files, operate with elevated permissions, and run without authentication on localhost. There have been over a dozen publicly disclosed MCP security incidents between July 2025 and April 2026, including a systemic design flaw in Anthropic's core MCP specification that affects over 150 million downloads.
What is the difference between probabilistic and deterministic guardrails?
A probabilistic guardrail asks the LLM to assess whether its own output is safe. Because the same model that generated the behavior performs the evaluation, it can be bypassed. Model-level guardrails were bypassed in 72% of test cases for Claude Haiku. A deterministic guardrail is code enforced outside the LLM's reasoning loop: an allow-list of permitted tool calls, a schema validator on tool arguments, a circuit breaker that throttles on abnormal call frequency. Deterministic guardrails block the action regardless of what the model generates.
Do I need a new security tool to pass this audit?
Several checks — process tree lineage testing, blast-radius assessments, MCP credential audits — can be run with your existing EDR and logging stack. The gaps most commonly surface in configuration and coverage. Where tooling gaps exist, CrowdStrike Falcon Shield (Spring 2026) and purpose-built agentic security platforms like Zenity address agent discovery, behavioral monitoring, and shadow AI governance. Evaluate against the specific gaps your audit surfaces before procuring anything new.