


How to Use ChatGPT, Perplexity, Gemini, and Claude to Build an IT Vendor Shortlist
Learn how to use ChatGPT, Perplexity, Gemini, and Claude to build an IT vendor shortlist, with copy-paste prompts and a protocol to verify AI claims.

Use the four engines as a sequenced pipeline: frame the category and requirements in ChatGPT, run cited comparison research in Perplexity, validate at depth in Gemini, and stress-test vendor documents in Claude. Then verify every load-bearing claim against primary sources before it reaches a scorecard — AI search tools are wrong on more than 60% of source-attribution queries.
Half of B2B software buyers now open an AI chatbot before they open Google. That figure reached 51%, up from 29% a year earlier, and the most recent Forrester buyer survey found that 94% of business buyers use large language models somewhere in the purchase process.
Across ChatGPT, Claude, Gemini, Perplexity, and Copilot, the estimated volume runs to 80 to 100 million B2B research prompts every day.
So the question is no longer whether you use AI to find IT vendors. You already do, or someone on your buying committee does. The question is whether your process produces a defensible shortlist or a confident-sounding list of the wrong names.
I have watched both outcomes. The difference comes down to treating these four engines as one interchangeable oracle versus running them as a pipeline, where each does the job it is actually good at and every claim gets verified before it reaches a scorecard.
That pipeline is what follows, with the prompts I use and the checks that keep the fabrications out.
Why Generic LLM Prompts Produce Bad Vendor Shortlists
Generic prompts fail for three structural reasons: knowledge cutoffs surface discontinued or renamed products as current; incumbent bias makes models recommend the market leader in 100% of trials when products look identical; and models fabricate plausible answers when they lack facts. A disciplined pipeline with verification corrects for all three.
Three structural problems sit underneath every weak AI-generated shortlist. Understanding them tells you exactly what your process has to correct for.
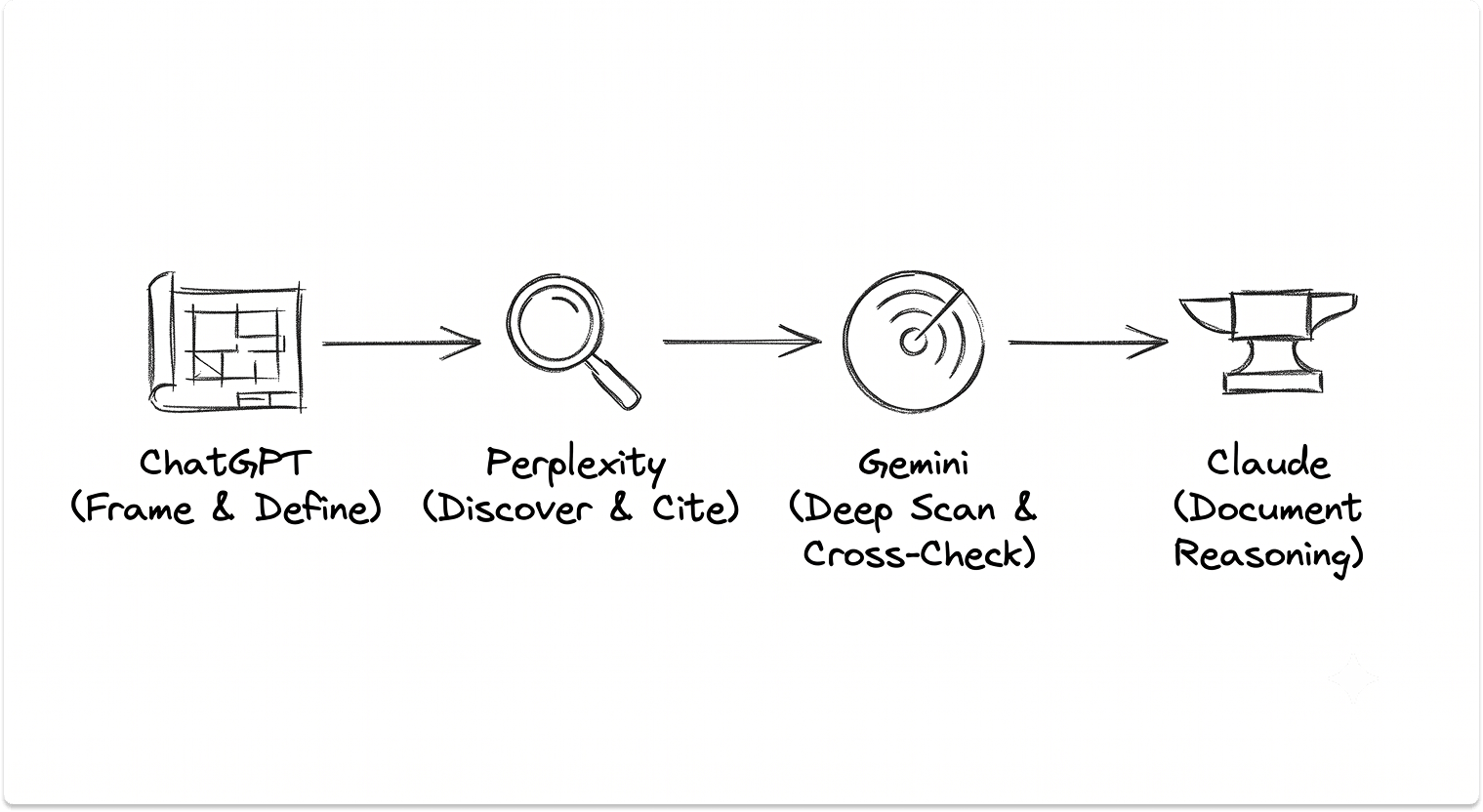
Match the Engine to the Stage: A Four-Tool Vendor Research Pipeline
Each engine has one job. ChatGPT frames the category and drafts requirements; Perplexity runs cited comparison research and discovers candidates; Gemini validates at breadth and drops reports into Google Workspace; Claude reasons over uploaded RFP responses and contracts. Run them in sequence because the order matters as much as the tool choice.
The core mistake I see is asking a single engine to run the entire search. Each of the four has a distinct strength, and the sequence matters as much as the tool.
ChatGPT: Frame the Category and Define Your Requirements
Use ChatGPT first, before naming any vendor. Its strength is converting a vague business need into a structured requirements set — must-have versus nice-to-have — and drafting clean RFP language. Treat any vendor names it produces as an untested hypothesis for Perplexity to verify, not a shortlist. Seed it with your real environment and constraints.
I reach for ChatGPT first, before I have a single vendor name in mind. Its strength is turning a fuzzy business need into a structured requirements set and a clear picture of how the category is organized. It drafts the must-have versus nice-to-have scaffold well, and it writes clean RFP language.
What it should not do at this stage is hand you the final vendor list. Its names are a hypothesis for Perplexity to test, nothing more. Seed it with your actual environment so the output reflects your constraints rather than a generic template.
I am an IT leader evaluating [category, e.g., a VMware alternative]for a company with [size, industry, key systems, compliance needs].
Do not name specific vendors yet.
1. Break this category into its core architectural approaches and explain the trade-offs of each.
2. Produce a requirements table with two columns: Must-Have (deal-breakers) and Nice-to-Have.
3. List the five hardest questions I should ask any vendor in this space before shortlisting.
Perplexity: Run the Cited Vendor Research
Perplexity is the discovery workhorse because every claim arrives with a clickable source, making it strongest for longlist building and cross-shopping. Its failure mode: the cited URL is usually real, but the page does not always support the attached claim. Keep the source open and confirm the text before trusting any capability.
Perplexity is the discovery workhorse because every claim arrives with a clickable source. This is where the longlist takes shape and where cross-shopping happens. For Perplexity vendor research to hold up, you have to understand its specific failure mode.
The URL it cites is usually real. The claim it attaches to that URL is not always supported by the page. So Perplexity earns its place in the pipeline only when you keep the source open in the next tab and confirm the page actually says what the answer claims.
Force it to attach a source to every capability, and make it flag currency explicitly.
Compare vendors in [category] against these must-haves:[paste your Must-Have list from ChatGPT].
Rules:
- Present results as a table, one vendor per row.
- Every capability claim must have a source link. If you cannot source a claim, mark it "unverified."
- Include at least two challenger or niche vendors, not only market leaders, and explain why each qualifies.
- Flag any vendor you are not confident is still independent and active as of this year.
That instruction to include challengers is deliberate. It is the direct counter to the incumbent bias described earlier.
Gemini: Validate at Depth and Inside Your Google Stack
Gemini is best for the wide, deep validation pass. Its Deep Research mode browses far more sources per query than the others, and reports export directly into Google Docs for committee annotation. Use it for breadth and as a second-opinion cross-check, since independent testing rates its citation accuracy below Perplexity's.
Gemini shines on the wide, deep pass. Its Deep Research mode browses far more sources per query than the others, and if your buying committee lives in Google Workspace, the finished report drops straight into a Doc your team can annotate together.
I also use it as a second opinion. Running the same shortlist question through a different engine surfaces the confident-wrong answers that any single tool produces.
Treat Gemini as a breadth-and-cross-check tool rather than a sole source of truth, since independent testing has flagged its citation accuracy as weaker than Perplexity's.
Run deep research on these shortlisted vendors: [names].
For each, report with sources:
- Known limitations and common implementation complaints
- Typical deployment timeline and integration requirements for [your core stack]
- Any pricing or licensing changes in the last 12 months
Organize as a comparison document I can export to Google Docs.
Claude: Stress-Test the Documents and Synthesize the Decision
Claude is for heavy document reading at the decision point. Paste in SOC 2 summaries, RFP responses, or contract terms and ask it to find gaps, contradictions, and unaddressed must-haves.
It reasons well over long documents and states uncertainty plainly. Its web search is a toggle so enable it or supply verified source text for live facts.
Claude is where I take the heavy reading. Paste in SOC 2 summaries, RFP responses, contract terms, or a vendor's own documentation, and ask it to find the gaps, contradictions, and unanswered must-haves.
It reasons well over long documents and tends to tell you plainly when it is unsure, which is exactly the behavior you want at a decision point.
Because its web search is a toggle rather than a default, either switch it on for live facts or give it verified source text to work from.
Here is [Vendor X]'s RFP response and security documentation[paste or upload].
Here is my Must-Have requirements list [paste].
1. Score the response against each must-have: Met, Partially Met, or Not Addressed, with the exact quote that supports your call.
2. List every claim that lacks supporting evidence.
3. Flag any contradiction between their security docs and their RFP answers.The Verification Protocol: Never Act on an Unchecked LLM Claim
Verify every load-bearing claim before it counts. Independent testing found AI search tools collectively wrong on more than 60% of source-attribution queries, with the worst fabricating links on 94% of answers.
The protocol: click each citation, confirm the page supports the claim, cross-run on a second engine, check primary sources, confirm currency, and escalate fabrication-prone facts to a human.
This is the step the generic "best AI tools" articles skip, and it is the one that protects your reputation. The numbers make the case.
When Columbia Journalism Review tested eight AI search tools on source attribution, they were collectively wrong on more than 60% of queries. The best performer still missed 37% of the time, and the worst fabricated links on 94% of answers.
A large 2026 citation study found fabrication rates ranging from 14% to 95% depending on the domain, and even retrieval-augmented systems with live web search invented 3% to 13% of their citation URLs.
Summarization on short, clean documents has gotten reliable, with the top models on Vectara's leaderboard sitting near 2% to 3%. But on enterprise-length documents, several frontier reasoning models still exceed 10%.
A hallucinated compliance certification or an invented integration on your scorecard is a decision defect, and it is your name on the decision.
Run every load-bearing claim through this protocol before it counts:
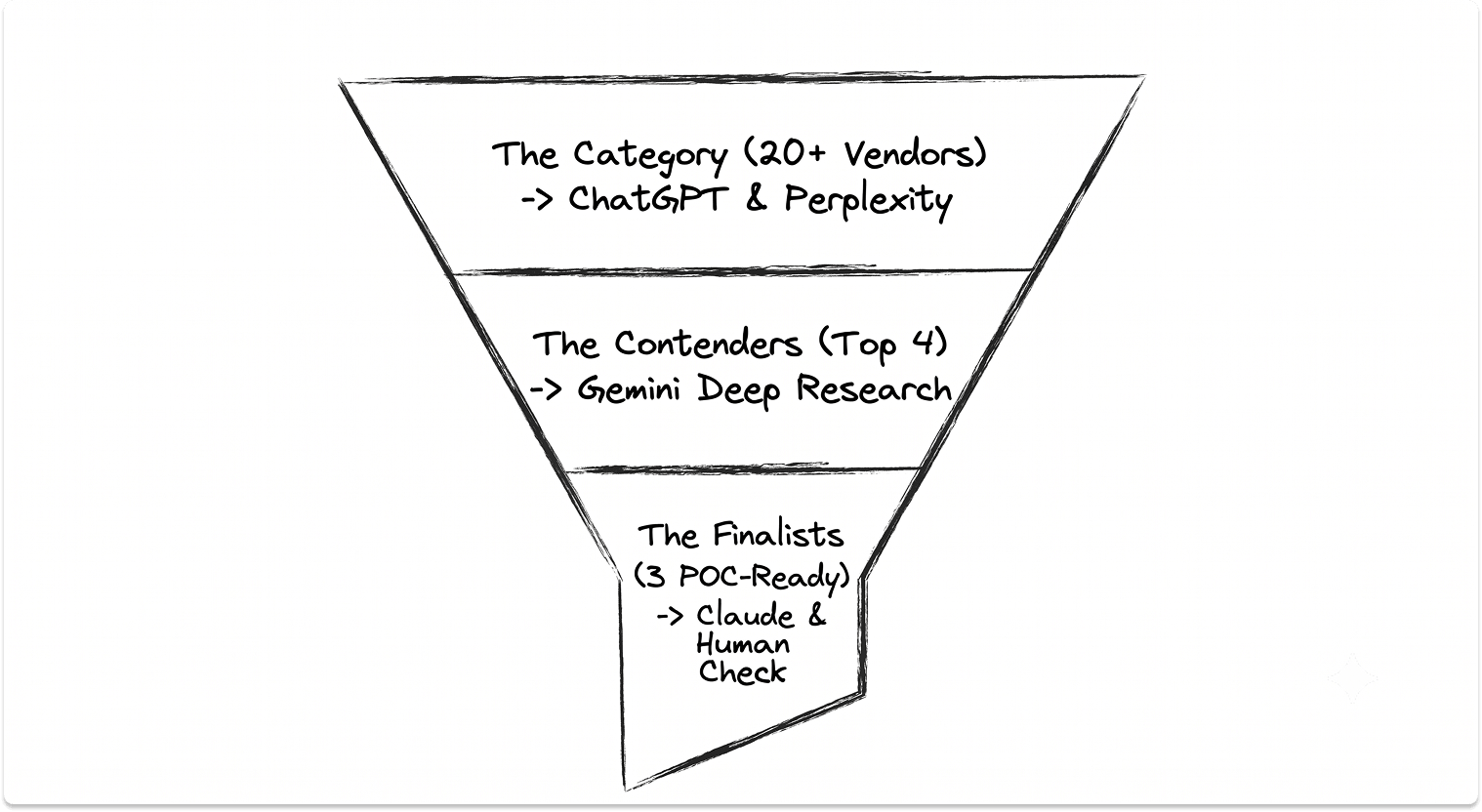
A Worked Example: From Blank Prompt to a Verified Shortlist of Three
A VMware-renewal scenario shows the pipeline end to end: ChatGPT frames the alternatives and a must-have list; Perplexity returns a sourced comparison of Proxmox, Nutanix, and Hyper-V; Gemini runs the deep pass on the top three; Claude stress-tests the finalists' documents. Verification removes an acquired "candidate" and an unsupported claim, leaving three checked names.
Consider a live scenario many teams are in right now. The VMware renewal arrived after the Broadcom change, the bill roughly tripled, and leadership wants a credible alternative on the table before the deadline. Here is how the pipeline runs.
I start in ChatGPT. It breaks the category into approaches, hyperconverged versus traditional hypervisor versus open-source, and produces a must-have list I refine: live migration support, existing backup-tool compatibility, a defined migration path off VMware, and a hard cost ceiling.
I move to Perplexity with that list. It returns a sourced comparison covering Proxmox, Nutanix, Microsoft Hyper-V, and a smaller challenger, with a link on every capability claim. Because I told it to flag currency, it notes one vendor's recent licensing change I would otherwise have missed.
Gemini runs the deep pass on the top three. It surfaces implementation timelines, known migration pain points, and integration requirements against our storage stack, and I pull the report into a Doc for the infrastructure team.
Then Claude stress-tests the two finalists' documentation against the must-haves. It flags that one finalist's RFP answer on backup compatibility is vaguer than their datasheet implies, scoring it Partially Met with the quote attached.
The verification protocol catches the rest. One "candidate" from an early ChatGPT draft turns out to have been folded into a larger vendor last year, so it never belonged on the list. A cited migration-tooling claim does not hold up when I open the vendor's own docs.
What remains is three verified names, each backed by sources I have checked, ready for a proof of concept. That last step, testing in your own environment, sits inside the broader IT vendor selection process.
Where the LLM Workflow Stops and Human Judgment Starts
AI compresses framing and comparison from weeks to days but cannot close the decision. G2 found 64% of buyers hit inaccurate AI recommendations often, then turn to peer reviews; buyers still average 16 vendor interactions before choosing. Treat any LLM shortlist as a hypothesis, then apply reference calls, POCs, and human judgment.
The pipeline compresses weeks of framing and comparison into days. It does not close the deal, and pretending otherwise is how buyers get burned.
The behavior data backs this up. G2 found that 64% of buyers hit inaccurate AI recommendations often or very often, and their immediate next move is to check peer reviews.
When 6sense studied why buyers now contact vendors earlier, the leading reason was to validate AI capabilities the models could not answer reliably. Buyers still average 16 interactions with the vendor they eventually choose.

So the shortlist an LLM builds is a starting hypothesis. It cannot judge fit against requirements you struggle to put into words, it cannot read cultural or relationship signals, and it cannot replace a reference call or a POC.
Use the engines to get to three strong candidates faster, then apply the human process that actually de-risks the decision.
There is also a limit no LLM crosses. It cannot keep you anonymous from vendors while you research, and it cannot tell you which challenger is genuinely solvent and vetted rather than simply well-marketed.
A curated, buyer-led marketplace like TechnologyMatch fills that gap, letting you evaluate vetted vendors on your terms and reveal yourself only when you choose to. It complements the AI workflow rather than competing with it.
Closing Thoughts
The advantage in 2026 goes to buyers who run the four engines as a disciplined pipeline with verification built in — frame in ChatGPT, discover in Perplexity, validate in Gemini, stress-test in Claude, and check every claim before it reaches a scorecard — rather than pasting one prompt into one engine and trusting the reply.
Everyone has access to these four engines. The edge in 2026 belongs to the buyers who operate them as a disciplined pipeline with verification built in, capturing the speed without inheriting the fabrications.
The buyers who lose are the ones who paste one prompt into one engine and treat the reply as fact. Frame in ChatGPT, discover in Perplexity, validate in Gemini, stress-test in Claude, and verify everything before it reaches a scorecard. Do that, and the first vendor call starts from a position of knowing rather than guessing.
A verified shortlist without the verification work
TechnologyMatch does the vetting for you. Search a curated catalog of IT vendors, stay anonymous while you evaluate, and message vendors when you're ready to talk. No cold calls, no spam, and this service is free to you.
FAQ
Which AI tool is best for researching IT vendors?
No single tool wins every stage. Use ChatGPT to frame the category and build requirements, Perplexity for cited comparison research, Gemini for deep validation and Google Workspace integration, and Claude to reason over uploaded RFP responses and contracts. The sequence matters as much as the tool.
Can I trust an AI-generated vendor shortlist?
Not without verification. Independent testing has found AI search tools wrong on more than 60% of source-attribution queries, and even web-connected systems fabricate a share of their citation URLs. Treat any LLM shortlist as a starting hypothesis, then click every citation and confirm claims against primary sources.
Why does ChatGPT recommend the same big-name vendors every time?
Models default to recognizable incumbents when the options look identical on paper. A 2026 study found the market leader was recommended in 100% of trials when products were indistinguishable. Supply real, sourced criteria and explicitly ask for challenger vendors, and that bias drops sharply.
How do I stop an LLM from recommending discontinued or acquired products?
Base models only know information up to their training cutoff, so they can present stale products as current. Turn on web search or Deep Research, ask the model what date its information reflects, and confirm each vendor is still independent and active through its own site, recent news, or Crunchbase.
What is the difference between using Perplexity and ChatGPT for vendor research?
Perplexity is grounded in live web results and cites a source on every answer, which makes it strong for discovery and comparison. ChatGPT browses only on demand and is better at framing the problem, structuring requirements, and drafting RFP language. Use them in sequence rather than choosing one.


