


AWS Bedrock vs Azure OpenAI vs Google Vertex AI: Enterprise AI comparison
AWS Bedrock vs Azure OpenAI vs Google Vertex AI compared on model access, provisioned throughput, latency SLAs, FedRAMP, data residency, RAG, and AI agents for enterprise teams.

The frontier models you reach through these three platforms land within a few points of each other on most production tasks, and any lead disappears at the next release.
The decision that sticks is the machinery underneath the model: how capacity is allocated and enforced, how the inference path is wired, where computation happens, and what the platform lets you ground against.
Those are the layers that determine your cost curve, your tail latency, and your compliance posture, and they are the layers most comparisons skip.
I have shipped workloads on all three. What follows is a technical differentiation across model access, throughput mechanics, latency and SLAs, data governance, retrieval, agents, safety, and customization.
If you are choosing a managed Kubernetes layer across these same clouds, the EKS vs AKS vs GKE trade-offs follow a similar logic: the model is rarely the lock-in, the surrounding control plane is.
How each platform is architected
Each platform answers a different first question, and that architecture decision propagates through everything else.
Amazon Bedrock is a model broker with a serverless control plane. A single API fronts foundation models from Anthropic, Meta, Mistral, Cohere, AI21, DeepSeek, Qwen, Stability AI, Writer, OpenAI, and Amazon's Nova family, with a marketplace of more than 100 additional models behind the same console.
The meaningful detail for engineers is that Bedrock now exposes two distinct API surfaces: the AWS-native bedrock-runtime with InvokeModel and the unified Converse API, and a newer bedrock-mantle endpoint that speaks OpenAI-compatible (/v1/chat/completions, /v1/responses) and Anthropic Messages formats. Existing SDK code can repoint at Bedrock without a rewrite, which lowers migration cost off a direct provider API.
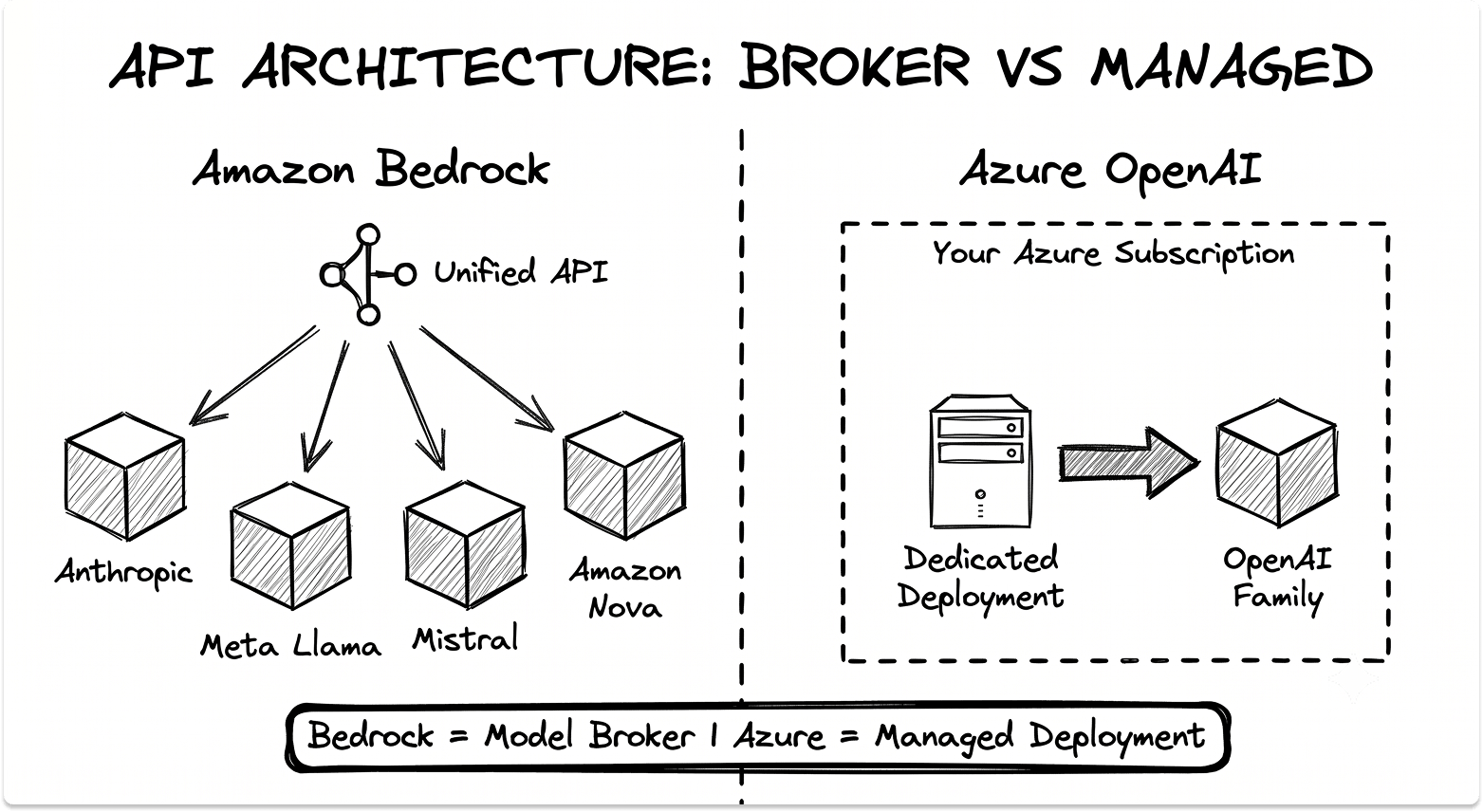
Azure OpenAI takes the opposite position. It is a managed deployment of OpenAI's models inside your Azure subscription and security perimeter, and the OpenAI family is the design center.
It now sits inside Microsoft Foundry, which adds Azure-direct partner models such as DeepSeek, Meta Llama, and Fireworks-hosted Kimi and MiniMax, plus Anthropic access through the same quota system. Models deploy into your chosen region rather than to a shared endpoint, which is the structural difference that gives Azure its data-residency story.
Google Vertex AI, rebranded at Google Cloud Next 2026 to the Gemini Enterprise Agent Platform, is built data-first. Gemini is native and Model Garden carries Claude (including Opus 4.8 and Sonnet 4.6), Llama 4, Qwen3, GLM, DeepSeek, and Mistral, with Gemini Pro offering a 1M-token context window.
The platform wires straight into BigQuery, Cloud Storage, and Looker, so AI runs next to the data warehouse instead of pulling data across a network boundary. The billing mechanics did not change with the rebrand.
Throughput and capacity: three units that do not convert
This is where the platforms diverge hardest, and where the unit you reserve changes your bill. Each offers pay-as-you-go for variable traffic and a reserved mode for predictable load. The reserved modes are not interchangeable.
Bedrock sells Provisioned Throughput in model-specific units, alongside on-demand, a Batch tier at a 50% discount, and cross-region inference that routes traffic across regions to dodge regional capacity limits at no added charge. Prompt caching cuts repeated-prefix input cost by up to 90%.
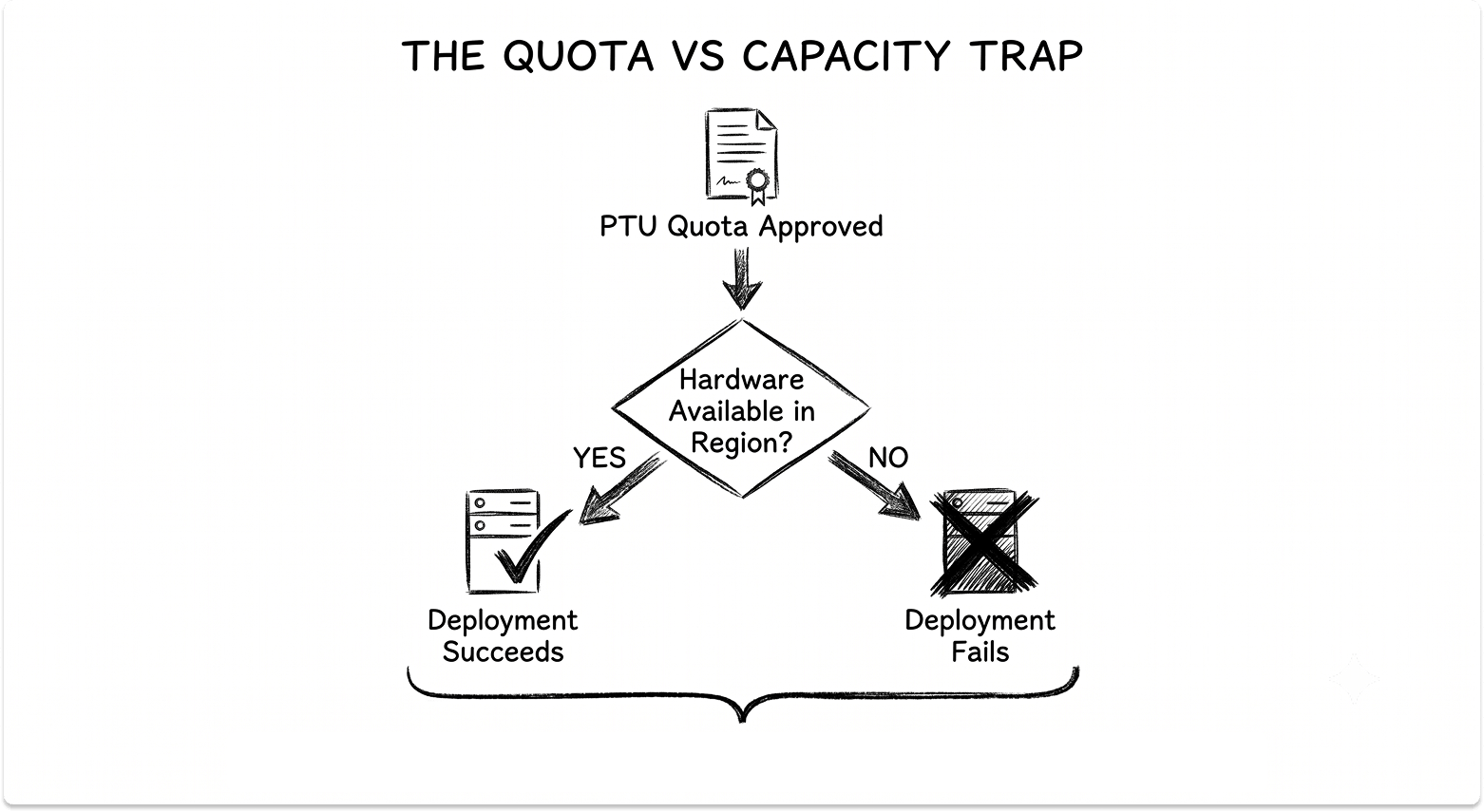
Azure sells Provisioned Throughput Units (PTUs), and two properties matter for sizing. PTU quota is model-independent: one pool covers any supported model in a region and deployment type. And the throughput a PTU yields depends on the model's input-to-output ratio.
For GPT-5, one output token counts as eight input tokens against your utilization limit; for GPT-4.1 the ratio is four to one, and cached tokens are deducted fully from utilization. PTUs come in Global, Data Zone, and Regional variants, billed hourly or through reservations.
Vertex sells Generative AI Scale Units (GSUs) with per-model burndown rates that normalize tokens, characters, and images into one throughput figure. Vertex enforces quota over a dynamic window rather than a hard per-second cap, so bursty traffic can briefly exceed the per-second rate as long as the window average holds.
Buy 25 GSUs of Gemini 2.5 Flash and you get roughly 67,250 tokens per second sustained. Vertex also added Priority PayGo, a tier between standard pay-as-you-go and reserved capacity that delivers steadier performance with no upfront commitment.
One trap repeats, and it is sharpest on Azure: quota is not capacity. Holding PTU quota means you are permitted to deploy that many units, but if the region lacks hardware at deployment time, the deployment fails. Confirm capacity before buying a reservation, and keep a permanent deployment sized to real traffic instead of scaling PTUs up and down.
Token pricing and the cost cliffs in the fine print
Top-of-catalog rates cluster closely. The differences that move a monthly bill are the cliffs and the platform overhead, so I will name them rather than restate price lists. These mechanics are a frequent reason AI/ML workloads quietly break a cloud budget.
On Azure, token rates are identical to calling OpenAI directly, but production deployments commonly add 15% to 40% through support plans, data egress, Private Link, and Log Analytics ingestion. That last item lands in the monitoring bill rather than the AI bill, and verbose logging left running in production compounds it.
On Vertex, two cliffs catch teams. Gemini 3.x reasoning models generate internal thinking tokens billed as output at the standard rate, so a request that reasons for 4,000 tokens before a 500-token answer charges you for 4,500 output tokens.
And Pro input pricing doubles once a prompt crosses 200,000 tokens, a hard threshold a long-document retrieval pipeline can trip on every request.
On Bedrock, inference rate is rarely the surprise. The add-on stack is. Knowledge Bases on OpenSearch Serverless start near $345 per month before a single query, Guardrails run $0.15 per 1,000 text units, and Flows bill $0.035 per 1,000 node transitions.
On a production bill these adjacent charges often run 20% to 35% of inference cost, and agentic workflows burn five to ten times the visible prompt-and-answer tokens once intermediate reasoning is counted. Claude through Bedrock matches Anthropic's direct pricing exactly, so the platform's value there is governance, not discount.
Across all three, do not commit to reserved capacity from a calculator. Run pay-as-you-go for 30 to 60 days, measure P95 hourly token throughput, then model the reserved option against real numbers. The same discipline that drives cloud cost optimization applies here.
Inference latency and what the SLA actually covers
Availability and speed are separate guarantees. Treat them separately, the way you would for any SLA you manage.
Azure publishes a 99.9% monthly availability SLA for Azure OpenAI, financially backed with credits, plus a latency SLA on Provisioned-Managed deployments covering token generation speed.
The standard pay-as-you-go endpoint carries no latency promise, and this is the gap that hurts: during peak demand you can see steady 429 throttling that never breaches the uptime metric because the endpoint was technically available. You paid full price for degraded service with no credit recourse. The fix is PTUs.
It helps to know the latency anatomy Azure documents: total time follows TTLT = TTFT + (time-between-tokens × tokens generated). When time-to-last-token rises in step with token count, that is expected behavior, not a regression.
When it rises without more tokens, check for capacity pressure. The single largest latency lever you control is max_tokens, since the model reserves compute for the full requested generation size.
Vertex added a tokens-per-second latency SLA to Provisioned Throughput, measured from first returned token to last, under its Online Inference SLA. Standard PayGo scales your throughput ceiling by rolling 30-day spend and caps at 30,000 requests per minute per model per region. The rule holds everywhere: pay-as-you-go buys availability, reserved capacity buys latency.
Data governance, residency, and isolation
Every platform commits contractually that prompts and responses do not train the foundation models. That box is checked across the board, which is the baseline any AI data privacy review should start from. Separation happens on network isolation, key control, and certification depth.
For US federal agencies and regulated contractors, FedRAMP High is the decisive first filter. Bedrock and Azure OpenAI hold it; Vertex's FedRAMP High is not generally available yet, which removes Vertex from those workloads regardless of Gemini's quality.
For healthcare, all three support HIPAA with private endpoints, so the compliance-heavy evaluation shifts to integration and cost. The Bedrock VPC endpoint model keeps protected health information inside your own VPC without traversing the public internet, which is why several clinical-document pipelines route Claude through Bedrock specifically.
Vertex carries one nuance worth reading into your data processing addendum: customer prompts and responses are not shared with third parties even when you call partner models like Claude through Model Garden, and computation is stateless. Its VPC Service Controls perimeter is the strongest native exfiltration defense of the three, and it pairs well with a broader Zero Trust architecture.
Retrieval architecture and grounding
Retrieval is where most enterprise value sits, because it keeps the base model fixed while feeding it your data at query time with source attribution. The architectures differ in how much they ask you to assemble.
Bedrock offers Knowledge Bases, a managed RAG pipeline that ingests from S3 and connectors like Salesforce and SharePoint into an OpenSearch Serverless vector store, with your choice of embedding and re-ranking models.
The newer Bedrock Managed Knowledge Base adds an agentic retriever that plans and runs multi-step queries across sources and exposes itself over the Model Context Protocol, so any MCP-compatible framework can call it without custom integration code.
Azure grounds through Azure AI Search, surfaced as the On Your Data pattern and through Foundry Agents grounding, keeping retrieval inside the Azure perimeter for residency-bound corpora.
Vertex grounds against Vertex AI Search, Google Search, and directly against BigQuery and Cloud Storage. If your corpus already lives in BigQuery alongside Snowflake or Databricks workloads, this removes the data-movement friction that otherwise dominates RAG integration cost, and it is the clearest technical reason analytics-heavy teams choose Vertex.
Agent runtimes
The center of gravity moved from single responses to agents that plan, call tools, and run multi-step work. The runtimes are built differently.
Bedrock splits the job. Bedrock Agents is the managed, low-code path with action groups, memory, and multi-agent collaboration under a supervisor. AgentCore is the framework-agnostic platform for CrewAI, LangGraph, LlamaIndex, or Strands.
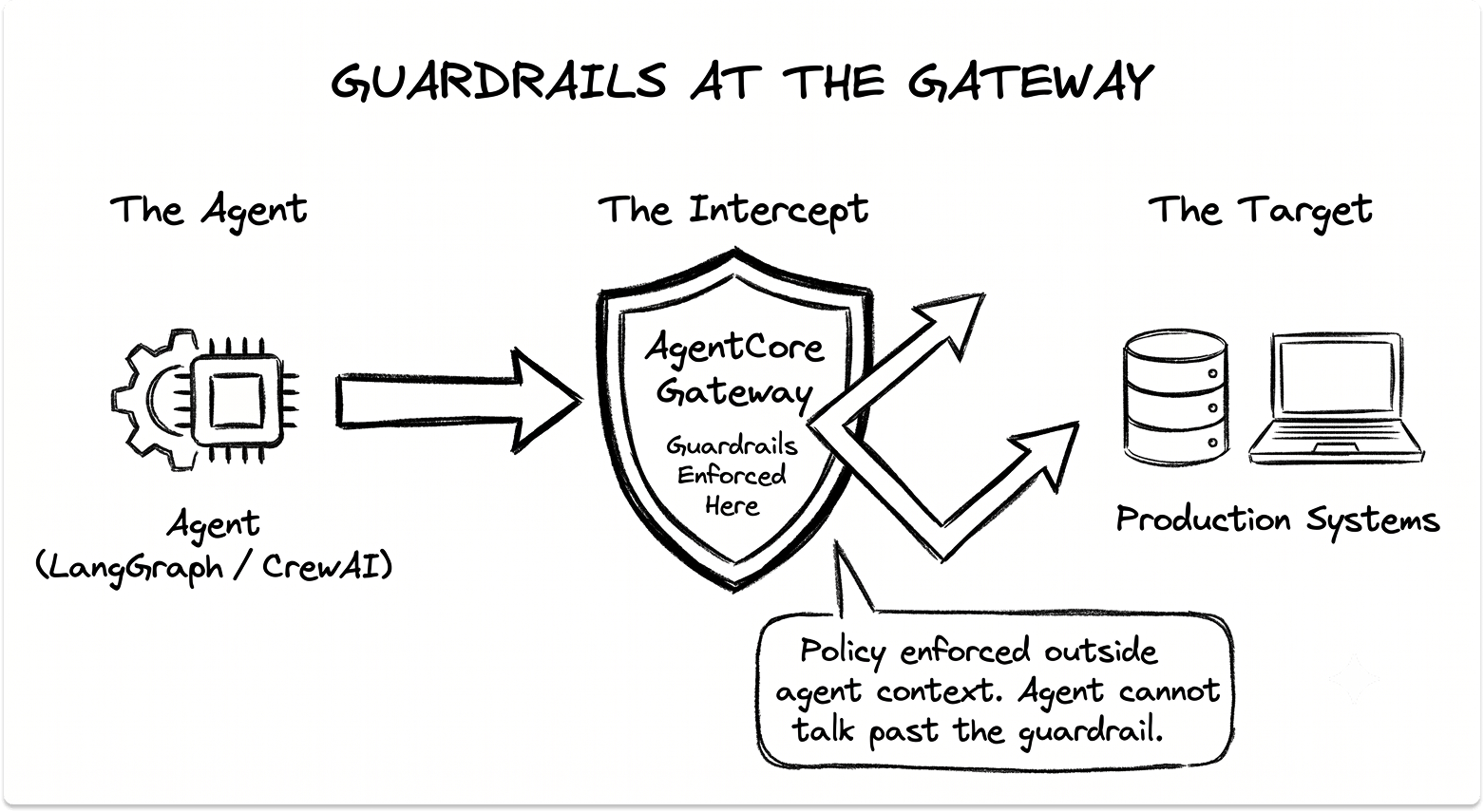
The architecturally interesting part is that AgentCore Gateway enforces Guardrails at the gateway layer, outside the agent's context, so the agent cannot see, reason around, or talk its way past them. It also exposes tools over MCP and ships observability and A/B testing. Before you wire agents into production systems, it is worth auditing the endpoint security stack they will touch.
Azure routes agents through the Foundry Agent Service, the supported replacement for the retired Assistants API, with native proximity to Microsoft 365, Teams, and Copilot.
Vertex offers Agent Runtime with sub-second cold starts, provisioning under a minute, and long-running operations up to seven days, plus Sessions and Memory Bank for state and a Cloud API Registry for the MCP servers an agent can reach. The seven-day operation ceiling is the differentiator for genuinely long-horizon workflows.
Safety and customization
Bedrock Guardrails is the most developed standalone control. It blocks up to 88% of harmful content, and its Automated Reasoning checks use formal logic to validate factual responses with up to 99% accuracy, which matters in regulated domains where a fabricated answer is a compliance event.
The ApplyGuardrail API works across any model, including self-hosted ones and even OpenAI or Gemini, so you can standardize one safety layer over a mixed fleet. Azure runs an ensemble content filter on prompt and completion, configurable but additive to latency.
Vertex provides configurable safety filters tied to the model and grounding stack. For multi-model environments, Bedrock's model-agnostic layer is the one I reach for first, and it pairs naturally with Claude Code security controls if Anthropic models anchor your stack.
On customization, the depth runs in a clear order. Vertex gives ML engineers the most complete toolkit: supervised fine-tuning, LoRA and other parameter-efficient methods, a distillation service that trains a smaller student from a frontier teacher, and a mature MLOps stack wired into BigQuery.
Bedrock supports fine-tuning plus Custom Model Import, which serves your own weights behind the same unified API with no infrastructure to manage, though custom models require Provisioned Throughput to serve.
Azure supports hosted fine-tuning of OpenAI models, billed by the hour for training and separately for hosting whether or not the variant serves traffic, which is why fine-tune spend is the line item teams most often lose track of on Azure.
The sequence that holds across all three: start with prompt engineering, add RAG when the model needs your data, and fine-tune only when behavior, format, or latency still falls short.
Use the questionnaire below to see which AI platform suits you
Choosing on technical fit
Platform choice beats model choice, and large teams often run more than one behind a unified gateway. Picking a primary still comes down to a few technical filters:
- FedRAMP High required: Bedrock or Azure OpenAI only. Vertex is out until its authorization goes GA.
- Data already in BigQuery: Vertex. Native warehouse grounding removes the data movement that would otherwise dominate retrieval cost, and the 1M-token Gemini context handles long documents in one pass.
- Migrating off a direct provider API with minimal rewrite: Bedrock via the Mantle OpenAI/Anthropic-compatible endpoint, or Azure if the source is OpenAI.
- Microsoft-native identity and tooling: Azure OpenAI, for Entra ID federation and Foundry Agent grounding into Microsoft 365.
- Mixed-model fleet needing one safety and capacity layer: Bedrock, for cross-model Guardrails and a single broker API.
- Long-horizon agents: Vertex Agent Runtime for seven-day operations, or AgentCore for framework-agnostic builds with gateway-enforced policy.
Before signing, get three technical answers in writing: where inference and any tuning data resides and the contractual guarantee behind it; the latency SLA on the exact deployment type you will run, not the headline uptime number; and the migration path off the platform, since a model swap is a config change but a control-plane swap is a project.
If you are weighing the broader cloud-tool layer underneath, the AWS Migration Hub vs Azure Migrate vs Google Cloud comparison covers the same three vendors from the migration side.
FAQ
What is the difference between AWS Bedrock, Azure OpenAI, and Google Vertex AI?
WS Bedrock is a serverless model broker that fronts Anthropic, Meta, Mistral, OpenAI, and Amazon Nova models through one API. Azure OpenAI is a managed deployment of OpenAI models inside your Azure subscription and region. Google Vertex AI is a data-first platform with native Gemini, a 1M-token context window, and direct BigQuery grounding. Bedrock optimizes for model breadth, Azure OpenAI for OpenAI depth and Microsoft integration, and Vertex AI for context length and data-stack proximity.
Which enterprise AI platform has FedRAMP High authorization?
AWS Bedrock and Azure OpenAI both hold FedRAMP High authorization in the relevant US government regions. Google Vertex AI's FedRAMP High is not generally available yet, so it is off the table for US federal agencies and regulated government contractors that require it. All three support HIPAA coverage with private endpoints for healthcare workloads.
How does provisioned throughput differ across Bedrock, Azure OpenAI, and Vertex AI?
AWS Bedrock reserves capacity in per-model Provisioned Throughput units. Azure OpenAI uses model-independent Provisioned Throughput Units (PTUs), where output tokens count more than input tokens against your limit (8 to 1 for GPT-5). Google Vertex AI uses Generative AI Scale Units (GSUs) with per-model burndown rates and enforces quota over a dynamic window rather than a hard per-second cap. On every platform, holding quota does not guarantee that hardware capacity is available at deployment time.
Which platform is cheapest for enterprise AI workloads?
Top-of-catalog token rates cluster closely, so the cheapest platform depends on your workload shape rather than the list price. Vertex AI Gemini Flash-Lite and Amazon Nova are the lowest per-token options for high-volume classification and extraction. The real cost drivers are structural: Azure's 15-40% platform overhead, Vertex's input-price doubling above 200K tokens and billed reasoning tokens, and Bedrock's separately metered Knowledge Bases, Guardrails, and Flows. Run pay-as-you-go for 30 to 60 days and size reserved capacity against measured P95 throughput before committing.
Which platform is best for RAG and building AI agents?
For retrieval, AWS Bedrock offers managed Knowledge Bases with an agentic retriever exposed over MCP, Azure OpenAI grounds through Azure AI Search, and Vertex AI grounds directly against BigQuery and Google Search, which suits analytics-heavy teams. For agents, Bedrock AgentCore enforces guardrails at the gateway layer outside the agent's context and is framework-agnostic, Azure's Foundry Agent Service integrates tightly with Microsoft 365, and Vertex Agent Runtime supports long-horizon operations up to seven days. Choose Bedrock for mixed-model fleets, Azure for Microsoft-native stacks, and Vertex for BigQuery-grounded and long-running agentic work.


