5 Problems That Surface After You Replace Your On-Prem SIEM
A technical guide for CISOs and security architects replacing an on-premises SIEM. Covers detection rule migration failures, cloud SIEM ingestion cost forecasting, SOAR playbook breaks, compliance retention gaps, and analyst productivity loss during parallel operation.
Cisco's $28 billion acquisition of Splunk in March 2024 accelerated a re-evaluation that was already underway across the SIEM market.
Organizations running on-premises Splunk SIEM, IBM QRadar, and LogRhythm had been questioning costs and roadmap confidence well before the deal closed. The acquisition sharpened those conversations.
Many have since signed contracts with new SIEM vendors. What they didn't account for was the scope of what moves with the platform. A SIEM sits at the center of your detection, response, and compliance stack.
Everything in your SOC points at it. Migrating it means renegotiating every one of those dependencies, simultaneously, with your environment still running.
These migrations are complex, resource-heavy, and time-consuming, often taking up to 15 months with extensive manual effort and cross-team coordination. The five problems below are the ones that consistently surface after the contract is signed, the kickoff call is done, and the real work begins.
What You're Actually Replacing
Before getting into where things break, it's worth being precise about scope.

Your SIEM is a platform that six operational layers depend on. Most of them are undocumented until the migration forces you to find them:
- Detection rules and correlation logic: Custom rules built in SPL, ARIEL, or AQL, encoding years of environment-specific tuning
- Data ingestion pipelines: Every log source connected via agents, forwarders, or API connectors configured to the current platform
- SOAR playbooks and automation workflows: Response logic built against the SIEM's alert schema and field naming structure
- Compliance log archives: Retained log data satisfying audit requiremxents, often spanning multiple years across frameworks
- Threat intelligence integrations: IOC enrichment, feed mappings, and STIX/TAXII connector configurations tied to the platform
- Analyst workflows: Query patterns, dashboards, saved searches, and escalation procedures built around one platform's interface and data model
Every layer requires active work during a migration. None transfer automatically.
Challenge 1: Detection Rule Migration Is a Rebuild, Not a Translation
Every security team I've seen go into a SIEM migration expects their detection rules to carry over in some form. Some SIEM vendors will tell you their migration tooling handles the heavy lifting. That's partly true and partly a sales position.
The underlying query languages aren't structurally equivalent. SPL (Splunk), ARIEL (QRadar), and YARA-L (Google SecOps/Chronicle) express correlation logic differently.
A Splunk tstats query built for high-volume netflow analysis doesn't have a clean KQL equivalent in Microsoft Sentinel. Manual translations are labor-intensive, error-prone, and time-consuming, potentially leaving organizations vulnerable during the transition. You don't adapt the rule. You rebuild what it was trying to detect.
Organizations with 200 to 500 active detection rules face significant analyst effort during the same period they're managing parallel collection infrastructure and validating detection parity.
Then there's the baseline problem. A portion of your current rule library is probably already broken before the migration begins.
CardinalOps' 2025 State of SIEM Detection Risk Report, analyzing over 13,000 unique detection rules across hundreds of production environments including Splunk SIEM, Microsoft Sentinel, IBM QRadar, and Google SecOps, found that 13% of SIEM rules are non-functional and will never fire, due to misconfigured data sources and missing log fields.
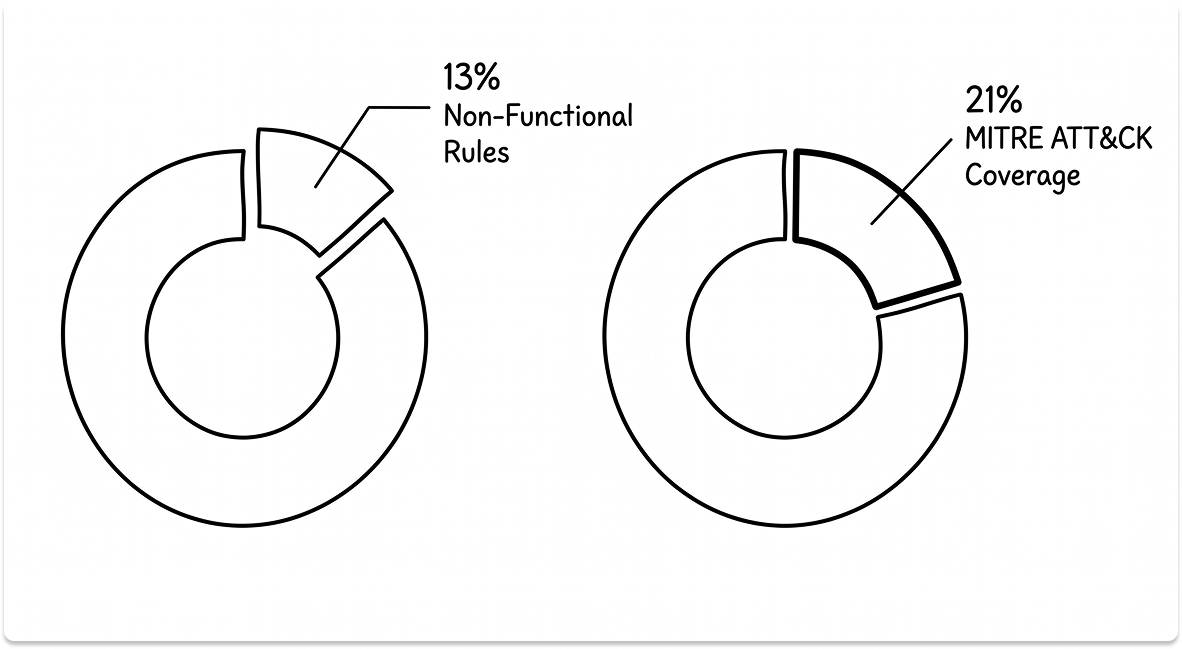
The same report found enterprise SIEMs cover only 21% of MITRE ATT&CK techniques on average, despite having more than enough telemetry to theoretically cover 90%.
Here's the critical part: broken rules don't throw errors. They just stop firing. You won't know a detection gap exists until you're in a post-incident review asking why an alert that should have fired three days ago never did.
What to do before you commit:
- Export your full rule library and run a 90-day activity audit. Every rule that didn't fire in that window is dormant. Most organizations find the majority fall into this category.
- Map active rules against MITRE ATT&CK techniques, then identify which of those techniques are covered by native detection content in the target platform.
- Get a written migration coverage statement from your prospective vendor, specific to your source platform. Ask them to define exactly what "covered" means in their methodology.
- Build the rule gap analysis into your project timeline before signing. If a vendor can't produce that pre-sale, treat it as a signal.
Challenge 2: Cloud SIEM Ingestion Costs Will Exceed Your Forecast If You Don't Audit First
On-premises SIEM software is typically licensed by infrastructure or capacity tier. Once the hardware is provisioned, the marginal cost of adding a log source is close to zero. Cloud SIEM pricing is built on a completely different model.
Every gigabyte ingested costs money, continuously. Microsoft Sentinel charges approximately $5.22 per GB at pay-as-you-go rates. A single misconfigured firewall, a new endpoint agent, or a Microsoft 365 audit policy change can double your daily ingestion overnight.
A 200-person company with standard Microsoft 365, firewall, and endpoint logging generates roughly 20 to 40 GB per day, costing $38,000 to $76,000 per year in ingestion. Add a CASB, a DLP tool, or verbose endpoint logging, and volume spikes to 80 to 100 GB per day, pushing annual costs to $152,000 to $190,000 for the same company.
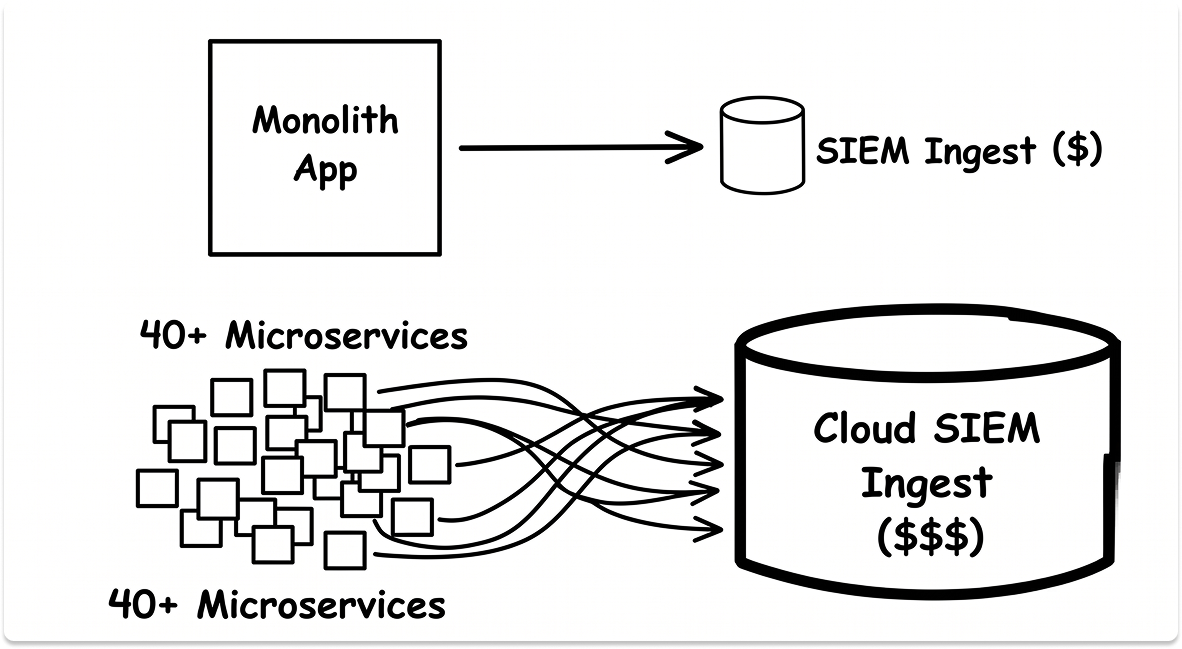
Cloud architecture decisions compound this significantly. Companies that moved to microservices between 2020 and 2024 saw their SIEM ingest jump three to five times without adding a single new application.
A monolith generates one set of application logs. The same application split into 40 microservices generates 40 sets of logs, plus inter-service tracing, API call logs, and service mesh telemetry.
What most teams realize only after the invoice arrives is this: the average organization queries less than 30% of its ingested data for security purposes. The other 70% sits in indexes, costing money per GB and never getting touched until it ages out. Switching SIEM tools doesn't fix that problem. It follows you to every platform.
What to audit before you sign:
- Pull current daily ingestion volume broken down by log source, not in aggregate. Identify your five noisiest sources by volume.
- Separate sources by query frequency: which are actively used in detection and investigations versus which exist purely for retention?
- Map each source to the target cloud SIEM's log tier options. Microsoft Sentinel's Basic Logs tier costs significantly less per GB but cannot feed scheduled analytics rules or real-time alerting.
- Run the volume forecast at 1.5x and 2x current levels. If the cost model breaks your budget at 2x, design your ingestion architecture before go-live, not after.
Challenge 3: SOAR Playbooks Don't Transfer. They Break.
SOAR playbooks are written against a specific data model. Alert field names, severity mappings, and entity schemas are all tied to the SIEM generating the alerts they act on. Change the SIEM, and the data model changes. Every playbook referencing a field from the old platform stops working.
CISA's May 2025 guidance on SIEM and SOAR platform implementation identifies playbook and workflow preservation as one of the most operationally critical aspects of any SIEM migration.
All active and relevant workflows and playbook components from the old SIEM platform must be replicated in the new one. A SIEM migration stress-tests how well the security organization knows itself.
Often, the actual migration process uncovers forgotten integrations with other security tools and network management systems. Replicated, in practice, means rebuilt.
The failure mode is a quiet one. If your playbook for isolating a compromised host references a field called src_ip and the new SIEM names it SourceIP, the playbook fails silently at runtime. The automated response action doesn't execute. The analyst isn't paged. The host stays on the network. No error logged. No flag raised.

What to audit before you migrate:
- Inventory every active SOAR playbook. For each one, document the upstream alert type it triggers from and every field it references.
- That field list is your rebuild scope for the new platform. Map each field to its equivalent in the target SIEM's schema before any cutover planning begins.
- Categorize playbooks by automated action type: network changes (firewall blocks, VLAN isolation), identity changes (account lockout, credential reset), and notifications. Network and identity automation carries the highest risk when it fails silently.
- Run automated response actions in audit-only mode on the new platform during the parallel validation window, until detection parity is confirmed.
Challenge 4: Compliance Log Retention Has a Gap Window. Document It Before It Happens.
A SIEM migration almost always includes a period where both platforms run simultaneously. Parallel operation of the legacy SIEM and new SIEM, driven by phased migration or log retention requirements, is one of the most commonly unanticipated costs of SIEM replacement.
During this window, your log retention posture is split across two systems with different retention configurations, different storage costs, and potentially different retention periods.
The compliance risk isn't that logs get deleted. The risk is that during an audit covering the migration window, you can't demonstrate a coherent chain of custody.
Auditors evaluating a PCI DSS environment don't care that you were mid-migration. They care whether the required log data exists and whether it's accessible.
The parallel validation window that migration best practices recommend typically runs 8 to 12 weeks.
During this period, configuration changes must be implemented across both collection stacks, schema updates require parser modifications in both platforms, and certificate management and file permission considerations arise when agents read from the same log sources.
Retention minimums vary by framework. HIPAA requires six years. PCI DSS requires one year of availability with three months immediately accessible. Any gap in those periods during the migration window is a material compliance finding waiting to happen.
What to define before cutover begins:
- Document migration window start and end dates in writing, shared with your compliance team before any infrastructure changes.
- Confirm the new SIEM's archival storage covers the required retention periods for every log source in your compliance scope.
- Avoid re-ingesting historical log data from the legacy SIEM into the new one unless your vendor provides a clear data integrity verification process. Corrupted re-ingested data in an audit is worse than clean data in a legacy system.
- If you're running an MSSP or external SOC, confirm in writing which platform is the system of record for each log source at each migration phase. Ambiguity here creates direct audit liability.
Challenge 5: Analyst Productivity Falls During Parallel Operation, and MTTD Rises With It
Running two SIEM solutions simultaneously isn't a risk mitigation strategy. It's an operational cost that degrades your detection capability during the period you need it most.
During parallel operation, analysts are triaging alerts from two interfaces. Correlation logic differs between platforms, so the same underlying event may produce two alerts with different severity ratings and different supporting context.
Analysts can realistically triage one. The other gets deprioritized. Alert noise compounds the problem further. Organizations without ongoing tuning see a 40% increase in false positives within six months. During a migration, tuning discipline on the legacy platform almost always deteriorates because engineering focus has shifted to the new environment.

Mean time to detect increases during this period. I've yet to see a migration where it didn't, and I've rarely seen that risk formally accounted for in a project plan or risk register.
There's a secondary issue that almost nobody addresses up front: detection engineering freeze. Once migration planning begins, your team should stop building net-new detection rules on the legacy platform.
Any rule written in SPL two months before cutover is a rule that gets rebuilt in KQL after cutover, adding scope mid-project. In practice, this freeze is almost never formally declared. Teams keep building on the old platform out of habit. It quietly expands migration workload and extends the timeline.
What to define before the parallel run begins:
- Declare a primary SIEM designation per use case before go-live. Analysts need one system of record for investigation, not two.
- Formally declare a detection engineering freeze on the legacy platform the moment migration architecture is confirmed.
- Set a hard sunset date for the legacy SIEM before the parallel run starts. Open-ended parallel operation always runs longer than planned.
- Track MTTD weekly during the parallel run. If it climbs more than 20% above baseline, the parallel configuration is generating a detection risk that needs addressing before the timeline extends.
Pre-Migration Checklist
Before you commit to any SIEM solution, complete these seven steps:
Questions to Ask SIEM Vendors Before You Sign
Most vendor conversations center on AI detection capabilities, platform roadmap, and total cost of ownership. The questions that expose real migration risk come after the demo.
- What is your documented rule migration coverage rate specifically for [my current platform], and how is that percentage calculated?
- Do you offer a pre-production ingestion audit that measures our actual daily volume before we commit to a pricing tier?
- How does your alert schema map to the field structure our current SOAR playbooks reference, and is playbook migration support included in your professional services scope?
- What does your migration support package include, and what is billed separately?
- What is your recommended parallel operation window, and what does your team actively do during that period to maintain detection parity?
- How do you handle legacy SIEM log data for compliance audit purposes during the migration window?
The SIEM vendors worth keeping on your shortlist answer these directly, without redirecting to a solutions engineer.
Looking for SIEM partners?
Before you commit to a solution, it's worth seeing your options and exploring if there are vendors who might be a better fit. Tell us what you're working with. We'll match you with the ones worth your time.
FAQ
How long does a SIEM migration take?
Most SIEM migrations take between 8 and 15 months from contract signing to full decommission of the legacy platform. The range depends on the size of the detection rule library, the number of active SOAR integrations, compliance log retention requirements, and whether the organization runs a structured parallel validation window before cutover.
What are the biggest challenges when migrating from Splunk to Microsoft Sentinel?
The three most common failure points are detection rule migration, ingestion cost forecasting, and SOAR playbook compatibility. Splunk's SPL query language does not translate directly to Microsoft Sentinel's KQL. Custom rules must be rebuilt, not converted. Ingestion costs at Sentinel's pay-as-you-go rate of approximately $5.22 per GB can significantly exceed on-premises Splunk licensing costs if daily log volume is not audited before go-live.
What happens to SOAR playbooks during a SIEM migration?
SOAR playbooks are built against the field schema and alert structure of the current SIEM. When the SIEM changes, the data model changes with it. Field names, severity mappings, and entity references that playbooks depend on will differ across platforms. Playbooks do not migrate; they must be rebuilt against the new schema. Automated response actions that fail silently, such as host isolation or account lockout, will stop executing without generating errors or alerts.
How do I calculate cloud SIEM ingestion costs before migrating?
Measure your current daily log ingestion volume broken down by individual source, not in aggregate. Separate sources by query frequency: which are actively used in detections versus which exist for retention only. Map each source to the target SIEM's available log tiers. Run cost projections at 1x, 1.5x, and 2x your current volume. Organizations that migrated to microservices architectures between 2020 and 2024 commonly see ingest volumes three to five times higher than expected due to inter-service telemetry.
How do you maintain compliance log retention during a SIEM migration?
Define the migration window start and end dates in writing before making any infrastructure changes, and share that documentation with your compliance team. Confirm the new SIEM's archival storage meets the retention minimums for every framework in scope. HIPAA requires six years; PCI DSS requires one year of availability with three months immediately accessible. Avoid re-ingesting historical log data from the legacy SIEM unless your vendor provides a verified data integrity process. Document which platform is the system of record for each log source at every phase of the migration.