The 10 IT Vendor Management Questions IT Leaders Are Asking in 2026
The 10 IT vendor management questions IT leaders are asking in 2026 around AI risk, usage pricing, shadow IT, vendor drift, and exit planning, answered.

IT vendor management has always been hard and it gets harder with rising vendors and rising technologies.
AI vendors with no standardized risk framework. SaaS pricing models that shift mid-contract. Shadow AI bypassing procurement faster than any policy can catch it. The questions IT leaders are asking today are not the ones most vendor management guides were written to answer.
I've pulled together the 10 questions that keep surfacing in practitioner communities, TPRM forums, and procurement conversations right now. These are not theoretical edge cases. They are active operational problems with real financial and security consequences.
1. How Do You Evaluate AI Vendors When Standard Security Questionnaires Don't Cover AI Risk?
A SOC 2 Type II report tells you a vendor's access controls and incident response procedures are in order. It says nothing about hallucination rates, training data provenance, prompt injection defenses, or whether your data trains the next version of their model for other customers.
Only 1 in 10 enterprises currently has an advanced AI security strategy in place, according to Flexera's 2026 IT Priorities Report. The gap is not a lack of awareness. It is a lack of the right questions.
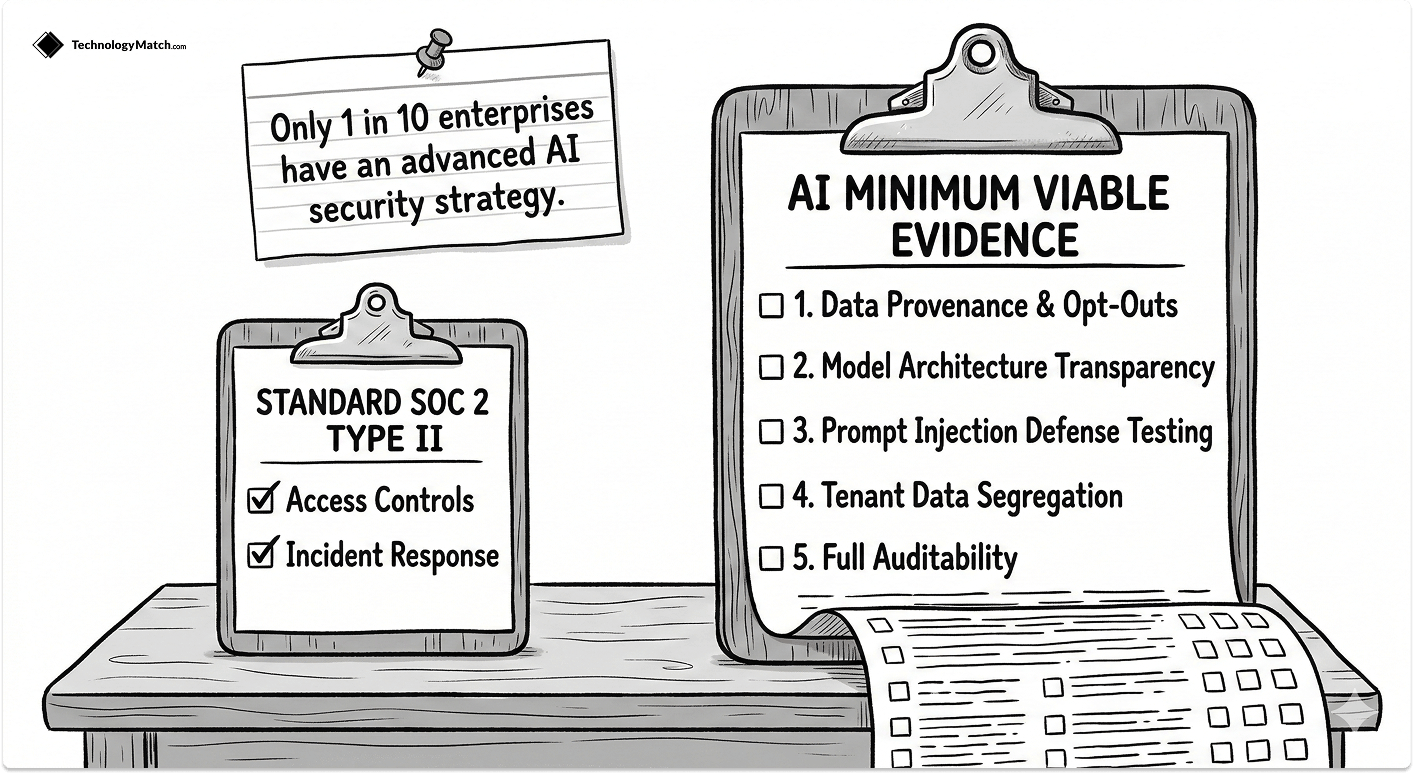
Build an AI-specific Minimum Viable Evidence layer on top of your standard due diligence. It covers five things your SOC 2 does not:
- Data provenance and training opt-outs: Get written, contractual confirmation that your tenant data — prompts, RAG context, retrieved documents, and model outputs — is excluded from the vendor's foundation model training pipeline.
- Model architecture transparency: Determine whether the vendor hosts a private model or wraps a public API. If it wraps OpenAI or Anthropic, that foundation model provider is a fourth party. Evaluate them too.
- Prompt injection and guardrail testing: Ask for documented testing methodology for prompt injection and jailbreaks, not a verbal assurance. A mature AI vendor will have this documentation.
- Tenant data segregation: Require architectural confirmation — not a policy statement — that your data never trains a model that serves another customer.
- Auditability: Confirm you can retrieve full conversation logs and model version history on request.
The EU AI Act compliance deadlines that began in February 2025 make compliance posture a verifiable data point for any vendor operating in EU markets. For others, ISACA recommends the NIST AI Risk Management Framework and ISO 42001 as structuring frameworks for AI-specific vendor assessments.
2. How Do You Detect Mid-Contract Vendor Drift Before It Becomes a Breach?
Your onboarding review was thorough. Eighteen months later, the vendor added two new cloud subprocessors, migrated to a different hosting region, and updated their privacy policy to allow de-identified training data use. A generic email went out. No one read it.
Mid-contract drift is the gap between the security posture you reviewed and the one currently running in production. Third-party involvement in data breaches doubled to 30% in 2025, up from 15% the year prior, according to Verizon's 2025 Data Breach Investigations Report. A vendor can pass a thorough review in January and suffer a material breach in March. Without continuous monitoring, you will not know until your annual assessment cycle.

Four things close that gap:
- Contract notification rights: Your DPA should require written notice of any new subprocessor within 30 days for high-tier vendors, plus an objection right that lets you pause scope expansion until you verify controls.
- Trust center automation: Subscribe to vendor trust center pages via RSS or a monitoring tool. Route changes directly into your ITSM or a dedicated Slack channel. Do not rely on vendor emails for this signal.
- External signal monitoring: Platforms like SecurityScorecard, BitSight, and UpGuard surface newly exposed credentials, certificate lapses, and vulnerability disclosures on a continuous basis, surfacing risks the vendor will not proactively disclose.
- Internal reassessment triggers: Define the events that kick off a mid-cycle review in writing: new subprocessors handling regulated data, breach disclosures from the vendor or their known subprocessors, a security rating drop below a defined threshold, or a material ownership change.
3. How Do You Control SaaS Vendor Costs When Pricing Shifts from Per-Seat to Usage-Based?
Per-seat contracts gave you predictability. Consumption-based pricing gives the vendor unlimited revenue expansion from existing accounts.
According to Metronome's 2025 State of Usage-Based Pricing report, 85% of SaaS companies now use usage-based pricing in some form, and 77% of the largest software companies have embedded consumption components specifically to expand revenue from current customers. AI workloads accelerate the problem. Token overages, API rate limits, and inference costs create billing surprises that per-seat governance models were never designed to catch.
The budget impact is documented. Zylo's 2026 SaaS Management Index found that 78% of IT leaders reported unexpected charges tied to AI features or consumption-based pricing in the past year, and 61% had to cut projects due to unplanned SaaS cost increases. Meanwhile, SaaS spend now averages $4,830 per employee, a 21.9% year-over-year increase, driven primarily by vendor price hikes and more complex licensing models.
Four governance tactics that actually work:
- Run a shadow audit before signing. Before accepting a consumption-based renewal, measure your own throughput for 30 days using your API gateway or cloud monitoring. Do not use the vendor's dashboard as your baseline.
- Negotiate annual drawdowns, not monthly quotas. An annual usage pool lets high-consumption months balance against low ones, eliminating overages from single-project spikes.
- Set your own alerts and rate limits. Configure internal consumption alerts at 75% and 90% of committed usage. Implement hard rate-limiting at the API gateway for non-critical workloads.
- Challenge bundled AI features. If a vendor is raising prices based on AI capabilities in your tier, require documented evidence of actual usage across your tenant. Non-adoption is a factual argument.
4. VARs vs. Direct Purchasing: Which Gives IT Managers More Leverage in 2026?
The assumption that direct purchasing always gives you the most control no longer holds. The channel landscape has changed enough that the right answer depends on what you are buying and what cloud commitments you already have.
According to Zylo's 2025 SaaS Management Index, an average of 13% of software spend now flows through marketplaces and resellers, a nearly 50% increase year over year. An average of 25% of applications are procured through these channels, an 86.8% increase. Cloud marketplaces — AWS, Azure, and GCP — are the main driver.

Cloud marketplaces have a specific advantage for organizations with committed cloud spend. Software procured through the marketplace counts against your Enterprise Discount Program or consumption commitment, creating an effective discount without negotiation. The limitation: marketplace contracts are standardized click-through agreements. Custom SLAs, liability caps, data residency requirements, and audit rights are not available.
VARs give you pricing intelligence you cannot easily get on your own. A VAR managing volume across dozens of comparable deals knows the actual market rate. The tradeoff is relationship distance and escalation paths for major incidents and strategic negotiations are mediated through the reseller.
Direct purchasing gives you the highest ceiling on contract customization. For tier-one critical vendors, it is worth the overhead. Change-of-control protections, AI subprocessor disclosure requirements, source code escrow, custom SLA credits, and executive escalation commitments all require direct contracting.
The practical framework: direct for tier-one critical vendors, marketplace where committed cloud spend creates a real discount with acceptable standard terms, VARs for administrative consolidation and benchmark pricing across your mid-tier portfolio.
5. How Do You Build a Vendor Evaluation Scorecard That Cuts Through Marketing Terminology?
"Process orchestration," "workflow automation," "low-code integration," and "intelligent process management" can describe the same capability or entirely different architectures. When evaluators score vendors based on their interpretation of vendor-specific language, the best marketer wins, not the best product.
The fix: remove vendor terminology from your evaluation framework entirely.
Define requirements as acceptance tests, not feature categories. Not "identity lifecycle management support," but: "User provisioned via SCIM appears with least-privilege role in under 60 seconds. Deprovision removes tokens and admin rights within 120 seconds. All actions captured in an audit log exportable to SIEM." Any vendor can be scored against that definition without interpretation.
Score live execution only. Run 5 to 8 scenario scripts using your actual data or synthetic equivalents. Vendor documentation counts for zero. Use an anchored 0-5 rubric where each score level maps to a specific, observable outcome, not evaluator impression.
Gate on non-negotiables before scoring begins. SSO/SAML, data residency, compliance certifications. Vendors that cannot demonstrate these exit before any scoring begins.
Build a terminology translation log. For each vendor, document what their marketing language means in their actual product: mechanism, constraints, live demo evidence. This record defends the selection to auditors and surfaces promises that did not survive onboarding.
6. What Should IT Teams Do When a Critical Vendor Gets Acquired Mid-Contract?
The announcement arrives by press release. Your vendor has been acquired by a private equity firm or a strategic buyer. What happens next depends on your contract and how quickly you move.
Reuters reported a rise in global M&A activity in 2025 with technology deals taking a significant share, confirmed by ChannelPro's 2026 vendor strategy analysis. The common post-acquisition sequence is predictable: product roadmaps freeze, support teams restructure, and pricing gets repackaged at the next renewal. For strategic acquirers, the most common outcome for point solutions is integration into the acquirer's platform, with the standalone product sunset over 18 to 36 months.
Pull your contract and find the change-of-control clause. Most SaaS agreements include one, granting a termination right, a renegotiation window, or both. If you have a clean exit right and the vendor is critical, do not exercise it reflexively. Use it as leverage. Its existence is worth more in a negotiation than its execution.
Request an updated DPA and subprocessor list within 30 days of close. The acquirer's infrastructure is not your vendor's infrastructure. For high-tier vendors, treat the acquisition as a mid-cycle reassessment trigger and run it through your standard risk review process.
Do not sign any "transition agreement" before extracting these four things: a price freeze for the remaining contract term, preservation of existing SLAs, confirmation that data residency commitments survive the transaction, and defined exit assistance terms if the product is eventually discontinued.
7. How Do You Govern Fourth-Party AI Risk When Your Vendor's Subprocessor Is an LLM?
Your vendor is SOC 2 certified. Their data center is in your required geography. Their standard subprocessor list shows familiar cloud infrastructure providers. What it may not show: the OpenAI or Anthropic API they route your support tickets through to power their AI-assisted summarization feature.
This matters beyond the corporate level. According to IBM's 2025 Cost of a Data Breach Report, 20% of organizations suffered a breach directly linked to shadow AI incidents, with those breaches costing an average of $670,000 more than standard incidents. The risk does not only come from your employees but it extends to how vendor employees handle your data internally.
Three contractual and operational controls close this exposure:
- Redefine "subprocessor" in your DPA to explicitly include any LLM or AI model API that processes, classifies, summarizes, or generates content using your data, regardless of whether the vendor treats it as a product feature rather than a data processing relationship.
- Require a Zero Data Retention agreement. The vendor must produce a ZDR agreement between themselves and their foundation model provider confirming your data is dropped after inference and not used for training. If they cannot produce it, require them to disable AI features for your tenant.
- Wire AI subprocessors into your change notification framework. Any new AI model API processing your data triggers the same 30-day notification and objection right as any other subprocessor change.
8. When Should You Consolidate IT Vendors and When Should You Diversify?
Both strategies have real evidence behind them, and applying either one across your entire portfolio simultaneously is where the analysis goes wrong.
The consolidation case is strong right now. According to Flexera's 2026 IT Priorities Report, 85% of IT decision-makers acknowledge IT visibility gaps as a significant threat; a six-point increase from the prior year. Over 70% of IT leaders report that business units are buying more cloud and SaaS than IT knows about. The consolidation pressure is coming from real governance failure, not strategy.
The concentration risk case is equally grounded. The CrowdStrike outage in July 2024 took down enterprises that had standardized entirely on its Falcon platform. Organizations with diversified endpoint protection or fallback capabilities recovered faster. Single-vendor dependency at scale is a board-level risk, not just an IT operational consideration.
The framework that resolves the tension:
- Consolidate commodity capabilities: Standard email, document storage, ticketing, routine infrastructure monitoring. The overhead of managing multiple vendors for the same commodity function is pure cost.
- Multi-vendor for strategic differentiators and high-severity risk layers: Specialized security tools, core data pipeline architecture, AI infrastructure. Best-of-breed gaps here are material to competitive position.
- Deliberate redundancy for critical infrastructure: Any capability where a single vendor failure would be operationally catastrophic requires designed redundancy, not just a backup clause.
The signal that consolidation has gone too far: a single vendor's pricing change becomes an existential negotiation for your team.
9. How Do You Stop Business Units from Bypassing IT Procurement Without Slowing Them Down?
Business units bypass IT because your process is slower than the alternative. That is the full explanation and understanding it correctly is what determines whether your response makes the problem better or worse.
Gartner found that 41% of employees acquired, modified, or created technology outside of IT's visibility in 2022, and projects that number will reach 75% by 2027. The AI acceleration has compressed that timeline. ChatGPT Plus costs $20 per month per user. Business units subscribe without a conversation and think nothing of it.

The financial exposure is growing. Flexera's 2026 IT Priorities Report found that 58% of IT leaders have already encountered issues specifically due to unsanctioned SaaS usage. And IBM's 2025 Cost of a Data Breach Report puts the additional breach cost from shadow AI at $670,000 per incident above the baseline.
The fix is not more restrictions. It is making the right path faster than the workaround.
- Time-box approvals: 48 hours for low-risk tools, five business days for medium-risk. Publish the SLA. When teams know they will get an answer quickly, they submit requests instead of signing up and hoping for the best.
- Build a living software catalog: Searchable, current, and honest about what is approved for what use case. When a team can see that their requested tool is already licensed or a near-equivalent exists, many bypass decisions never happen. A stale catalog is worse than no catalog.
- Route by risk, not through a single gate: Low-risk tools auto-approve against the catalog. Medium-risk goes to a lightweight security review. High-risk goes to the full committee. When every request hits the same heavyweight process regardless of sensitivity, the process itself becomes the incentive for bypassing it.
- Intervene at the point of access: Use CASB or enterprise browser tooling to surface a redirect when someone navigates to an unsanctioned tool, rather than a hard blocked error screen. Guidance at the moment of decision changes behavior more effectively than policy documents.
10. How Do You Build an IT Vendor Exit Plan Before You Need One?
By the time most IT teams ask "what would it take to leave this vendor?", the answer is: more than we can afford right now. The renewal happens under protest. Exit planning built reactively is not exit readiness, it is a negotiating disadvantage.
Exit readiness means that at any point in a vendor relationship, you can articulate your migration options, estimate the switching cost, and enter a renewal from genuine optionality.

Start the exit documentation at onboarding. Record the data export format and delivery mechanism, the API dependencies your internal systems have built against this vendor, the integrations that would require rebuilding during a transition, and the realistic lead time for a replacement to reach functional parity. This becomes your exit readiness record.
Negotiate data portability at signing, not at exit. Push for explicit terms: your data is exportable on demand in an open, documented format and not a proprietary schema requiring the vendor's tooling to read. Most vendors do not offer this by default but will accept it if asked directly.
Build exit assistance into the contract as a defined deliverable. Specify hours of technical support committed, data delivery SLAs, and format standards. A generic "exit assistance" clause with no specifics is unenforceable.
Test exit readiness annually. Once a year for high-tier vendors, run an internal exercise: if this vendor announced a 40% price increase tomorrow, what would we do? This surfaces integration debt you did not know existed and keeps your switching cost estimate current.
The paradox of exit planning is that the better your exit readiness, the less likely you are to need it. A vendor who knows you have documented alternatives, a tested migration path, and contractual portability rights will price and behave accordingly.
Looking for IT partners?
Find your next IT partner on a curated marketplace of vetted vendors and save weeks of research. Your info stays anonymous until you choose to talk to them so you can avoid cold outreach. Always free to you.
FAQ
What is IT vendor management and why does it matter in 2026?
IT vendor management is the end-to-end process of selecting, contracting, monitoring, and offboarding the third-party tools and services your organization runs on. In 2026 it matters more than it used to because the average enterprise runs hundreds of SaaS tools, AI vendors are introducing risk categories that traditional frameworks don't cover, and third-party breaches now account for 30% of all incidents according to Verizon's 2025 DBIR.
How do you evaluate AI vendors differently from standard SaaS vendors?
Layer an AI-specific Minimum Viable Evidence check on top of your standard due diligence. This covers five things SOC 2 does not: training data provenance, model architecture transparency, prompt injection defenses, tenant data segregation, and output auditability. For any vendor whose outputs influence business decisions, this layer is non-negotiable.
How do you prevent shadow IT without blocking the teams that depend on fast tool access?
Speed is the lever. Time-box approvals to 48 hours for low-risk tools and five business days for medium-risk. Maintain a searchable, current software catalog so teams can find approved alternatives without submitting a request at all. Route by risk rather than running every request through the same heavyweight process.
What rights do you have when a critical SaaS vendor gets acquired?
Your rights depend on what your contract says. Most SaaS agreements include a change-of-control clause granting a termination right, a renegotiation window, or both. If you have a clean exit right, use it as leverage rather than exercising it immediately. Request an updated DPA and subprocessor list within 30 days of the acquisition close, and do not sign any transition agreement before locking in a price freeze and SLA preservation.
When should IT leaders consolidate vendors versus maintaining a multi-vendor strategy?
Consolidate commodity capabilities — email, storage, ticketing, routine monitoring — where multiple vendors are doing the same job and the overhead is pure cost. Keep a multi-vendor approach for strategic differentiators and high-severity security layers where best-of-breed gaps are material. Build deliberate redundancy into any capability where a single vendor failure would be operationally catastrophic.